The policy section of the village pump is intended for discussions about already-proposed policies and guidelines, as well as changes to existing ones. Discussions often begin on other pages and are subsequently moved or referenced here to ensure greater visibility and broader participation.
If you wish to propose something new that is not a policy or guideline, use Village pump (proposals). Alternatively, for drafting with a more focused group, consider starting the discussion on the talk page of a relevant WikiProject, the Manual of Style, or another relevant project page.
For questions about how to apply existing policies or guidelines, refer to one of the many Wikipedia:Noticeboards.
If you want to inquire about what the policy is on a specific topic, visit the Help desk or the Teahouse.
This is not the place to resolve disputes regarding the implementation of policies. For such cases, consult Wikipedia:Dispute resolution.
I am an AMPOL editor and I often see articles with party affiliation assumed in the infobox. For instance, Adriana Kugler's infobox states that she is a Democrat, but no inline citation is provided. On the other hand, Todd Blanche does provide a citation for having registered as a Republican. I am questioning the purpose of this parameter for individuals who are not directly associated with politics—in other words, their profession does not pertain to being a politician or political consultant. "If relevant" in the {{Infobox person}} documentation is rather vague. The misuse of this parameter warrants some action.
The rationale for removing the party affiliation parameter is similar to the RfC over the religion parameter. As was stated then, "This would be consistent with our treatment of sexual orientation and various other things we don't include in infoboxes that are matters which may be nuanced, complex, and frequently controversial. The availability of a parameter encourages editors to fill it, whether they have consensus to do so or not, regardless of instructions in template documentation to gain consensus first; new and anon IP editors generally do not read documentation, they simply see a "missing" parameter at article B that they saw at article A and add it." elijahpepe@wikipedia (he/him)16:38, 10 August 2025 (UTC)[reply]
Oppose, and I note that both of the examples given in the original RFC question are "political" BLPs (both of them were political appointees in a system that expects appointees to come from the president's own political party) – people who very much are "directly associated with politics". Whether an inline citation is needed directly in the infobox depends on the usual Wikipedia:When to cite rules, namely whether the information is also present and cited elsewhere in the article. While political party affiliation can be "nuanced, complex, and frequently controversial", it is usually not, especially for people, such as political appointees, for whom this is actually relevant. "If relevant" appears in the documentation for {{infobox person}} more than a dozen times. If you can figure out whether to add |employer= or |height= or amateur radio |callsign= "if relevant", then you can probably figure out whether to add |party= "if relevant", too. WhatamIdoing (talk) 04:12, 13 August 2025 (UTC)[reply]
Oppose - mostly per Thryduulf. If it's used to signify some sort of political engagement (such as Kugler and Blanche being appointees in a political appointments system), I think it's 100% relevant and should be included. For other biographies it's probably relevant if it's matched by relevant text in prose (i.e. a celebrity who is also openly a member of and advocates for a political party). AlexandraAVX (talk) 09:53, 5 September 2025 (UTC)[reply]
I would say that unless they are running/elected in a position that requires a political affiliation to be made as part of the election process so that we have a clear basis to document it, this should be left out of the infobox and explained in the prose. Masem (t) 16:41, 10 August 2025 (UTC)[reply]
I think that if they are explicitly running as a candidate for/in affiliation with a given party, and this is cited in the pose, then it should be in the infobox. Otherwise it should not be. Thryduulf (talk) 16:56, 10 August 2025 (UTC)[reply]
I agree too. Too often I see a supposed party affiliation being added to judge infoboxes (Scalia, for example), based not on party registration or self-declaration but by some third party claiming it, and that opinion being claimed as a RS. Wehwalt (talk) 17:23, 10 August 2025 (UTC)[reply]
I am thinking of many local elections that are intended as non-partisan positions, though candidates often assert their position in their campaign materials, in comparison to partisan offices that usually require party primaries to be elected to. In the latter case, the political affiliation is part of the election process and can't be disputed (making it fair to include the infobox). Masem (t) 17:33, 10 August 2025 (UTC)[reply]
If someone is explicitly running on a partisan position then that position should be in the infobox. Even if the position is intended to be non-partisan if someone is running on a partisan platform then it is de facto partisan. The job of Wikipedia is to represent what the reality is, not what it is/was intended to be. Thryduulf (talk) 17:57, 10 August 2025 (UTC)[reply]
I would be more clear in this comment and state that the infobox should be following what sources say. Brad Schimel was nonpartisan in the Wisconsin Supreme Court election earlier this year, but he was described as a Republican across various outlets. elijahpepe@wikipedia (he/him)18:27, 10 August 2025 (UTC)[reply]
That's exactly a situation that I would *not* include the political affiliation in the infobox, because that's not a requirement for running in that election. In prose, absolutely. Its the same reason we restrict calling out religion in the infobox for only those people who's careers are specifically tied to the church/equivalent body of their religion, though we are free to include any stated religious beliefs in the prose of the article. Masem (t) 04:11, 11 August 2025 (UTC)[reply]
Schimel is in an interesting position because he ran as a Republican in the Wisconsin attorney general elections he was involved in. Most of the cases where a politician running for a non-partisan office is clearly affiliated with a party involve prior elections. I was reading a local news report from Wisconsin that made it clear that Schimel was de jure non-partisan. In cases where a candidate explicitly says they are of a certain party but they are running for office in a non-partisan role and they have not run in any other elections where they would be a candidate for that party, then that should not be in the infobox. elijahpepe@wikipedia (he/him)19:32, 11 August 2025 (UTC)[reply]
For a given individual, in some cases it's clear that they're "directly associated with politics," in some cases it's clear they aren't, but there are some people/positions where it's unclear. Todd Blanche is someone I'd put in the third group. He is a political appointee in an ostensibly non-political position, but in this administration, it seems that the position is political as well. I don't think political party is a "nuanced, complex" issue. I also don't think people should be adding this info without an RS. FactOrOpinion (talk) 02:24, 11 August 2025 (UTC)[reply]
I would argue that Blanche should not have "Republican" in his infobox. He is not a politician nor a political advisor. The argument that the "position is political" is a reach from what is being suggested here. Wikipedia shouldn't make its own conclusions. In reliable sources, Blanche might be described as a Trump loyalist, but not a Republican, a rather vague term that doesn't encompass Blanche's fealty to the president. The prose can handle describing Blanche properly. elijahpepe@wikipedia (he/him)04:10, 11 August 2025 (UTC)[reply]
I think we should limit listings of party affiliation to people who ran for office as a candidate for the party or people who served as officials of the party. I have seen party affiliation listed for people who served in political office in a position that was elected on a non-partisan basis, I do not think that is justified. There are of course people who have had multiple party affiliations. If they served in office for multiple parties that can be listed. One thing to keep in mind is on occasion a member of one party has appointed people from a different party to their cabinet, so even cabinet members we cannot assume they share the party of the president. This is even more clear in cases or any sub-cabinet position, for judges many times so. The same probably applies even more so to people who serve on the cabinet of governors. Many mayors and other local officials in the US are elected on a non-partisan basis.John Pack Lambert (talk) 15:57, 11 August 2025 (UTC)[reply]
I don't think there is a one-size fits all solution. There are the obvious cases, candidate runs as a partisan in a partisan election. And on the other side, there are non-partisans who run in non-partisan elections. But, there are many people who may be known (either in independent sources or verifiable non-independent sources) as a partisan. And, there are individuals who run as a partisan in a partisan election who change parties or disaffiliate at some point after that election. And, for many subjects, there are BLP considerations to account for. --Enos733 (talk) 16:07, 11 August 2025 (UTC)[reply]
Political party is a voluntary act, not something that can be otherwise discerned, even by RSs. Unless there is evidence of voluntary affiliation, through registration to vote or entering a party primary that requires party membership, or being a party official of some kind, I would exclude. RSs without evidence of this are just partisan name callers. Wehwalt (talk) 17:22, 11 August 2025 (UTC)[reply]
If this is an RfC then it needs to be formatted and advertised as such. If it's just a discussion, perhaps in advance of a potential RfC, it needs to be relabeled. ElKevbo (talk) 00:30, 12 August 2025 (UTC)[reply]
The two examples provided are political BLPs and the infobox used is {{Infobox officeholder}}, not the generic {{Infobox person}}. Party affiliation is a basic and often uncontroversial piece of information for office holders. I appreciate that there may be more complexity with non-partisan state and local races and political appointees whose personal party affiliation may differ from that of the leader or body who appointed them. I agree with the comments above that someone like Sydney Sweeney should not have their party affiliation listed; if relevant and appropriate per WP:DUE and other applicable standards it can be discussed in the article body. If this is meant to be an WP:RFCBEFORE discussion, which would be helpful, it should be clarified that this does not apply to {{Infobox officeholder}}. I'm not yet convinced party affiliation should be completely deprecated from {{Infobox person}} but I may get there. It is inappropriate for most public figures who are not/have not been office holders who are not primarily known for political, partisan work. For folks known primarily for and associated with politics but who are not office holders, like commentators and strategists, it may be case-by-case. --MYCETEAE 🍄🟫—talk18:32, 13 August 2025 (UTC)[reply]
It really seems like this is a field that belongs in office holder infoboxes or modules with a start/end, and not for a generic person. I'm really struggling to think of situations where party seems appropriate for a person. Even for non-office holders who are clearly very partisan, it seems like the better way to do it would be to have it in the occupation or known for fields. Something like "occupation: <party> strategist", or "known for: <party> political writings" or similar. That strikes me as more neutral and verifiable for a potentially nuanced fact like affiliation. Driftingdrifting (talk) 17:07, 21 August 2025 (UTC)[reply]
I think for info boxes we should only ever list party affiliation for people who held public or political office, and not list it for people whose primary office was a non-partisan elected office.John Pack Lambert (talk) 13:36, 15 August 2025 (UTC)[reply]
If we did want to partisan affiliation to a non-political person's infobox, we'd have to weed through what to make of people who are registered with one political party, but have given significant donations to candidates of a different party; or who are registered as (say) a Democrat but who ran for political office on the Green Party ticket 15 years ago; and other combinations like that. I think it gets complicated quickly and it would be better to avoid it altogether. Just askin' for trouble. Novellasyes (talk) 18:06, 19 August 2025 (UTC)[reply]
We had an RFC earlier this year around how to handle LLM/AI generated comments. That resulted in WP:HATGPT after further discussion at WT:TPG. Recently, an editor started a requested move using LLM generated content. I ran that content through two different AI/LLM detection utilities: GPT Zero says "highly confident", and 100% AI generated; Quillbot stated 72% of the text was likely AI generated.
Should HATGPT be expanded to allow for the closure of discussions seeking community input (RFC/VPR/CENT/RFAR/AFD/RM/TFD/RFD/FFD/etc) that are started utilizing content that registers as being majority written by AI?
I’m hesitant still with suggesting the use of gptzero except as additional evidence alongside with conclusive proof. But otherwise I’m always of opinion that most use of LLM in discussion is a bad faith usage of editor time. Bluethricecreamman (talk) 00:57, 12 August 2025 (UTC)[reply]
As I say every time things like this come up, the focus is completely wrong. We really should not care whether it is or isn't AI-generated, that's just wasting everybody's time trying to determine something that is irrelevant. If the proposal is understandable, relevant to the page it's on, isn't just rehashing something that's already been discussed to death (even if you disagree with it) then whether it was written by a human or machine couldn't be less relevant: deal with it as a good-faith contribution unless you have evidence it is not (use of an LLM is not evidence of good faith or of bad faith, it's completely independent of faith). If it is in bad faith, not understandable, trolling, rehashing a settled discussion, etc. then close it to avoid wasting time - this applies regardless of whether it is LLM-generated or human-generated. One of the many advantages of this approach is that it doesn't require any changes to policies or guidelines, because that's how Wikipedia has worked for many years. Thryduulf (talk) 01:00, 12 August 2025 (UTC)[reply]
"Fair" points perhaps, but not good points. Real editors who could be doing real things to benefit the project should not have to spend their time parsing machine-generate bloat in the hope that it will turn out to be the one-in-fifty case that isn't anywhere from fatuous vacuity to bullshit hallucination. The OP's linked example is an unfortunately poor exemplar of the problem, but anyone who's been active in project space over recent months has seen examples of text which makes you angry that someone expected you to waste your time reading it. You know how you can tell a tsunami is coming because the ocean suddenly recedes, leaving asphyxiating fish flopping on the sand? That's the stage we're at right now. We should respond to AI-generated text the way we'd respond to text in Klingon: tell the author to come back when they can write in English. EEng01:32, 12 August 2025 (UTC)[reply]
And take a look at this [1] ANI discussion for a truly epic example of how one AI-drunk incompetent can waste hours of the time of a dozen competent editors. `EEng02:41, 13 August 2025 (UTC)[reply]
"AI-drunk" reminds me of drunk driving. Cars a powerful and dangerous tool. We have licenses to operate, competence restrictions (age, eyesight), training courses, rules of the road, consequences for violations, etc.. the alternative is ban cars entirely because horses, public transport and walking work fine. -- GreenC04:37, 15 August 2025 (UTC)[reply]
Except we don't have licenses, competence restrictions, training courses, rules of the road, consequences for violations, etc. for AI. All we have is doofuses careening left and right, knocking down pedestrians, tearing up the pavement, frightening the horses, jamming the roadways with their vehicles actually headed nowhere, and poisoning the air with noxious fumes. So yeah, until those issues can be addressed AI should be banned, and walking, cycling, horses, and public transit -- which have served WP very well to date -- will have to continue serve until AI gets to the point that it can magically transform those lacking competence in English, and/or an understanding of what an encyclopedia is, into useful contributors. EEng23:39, 21 August 2025 (UTC)[reply]
I agree. LLMs are getting better, and we will very soon be unable to spot their output.[2] We need to deal with problem posts and edits the way we always have. Donald Albury01:43, 12 August 2025 (UTC)[reply]
Some guy at some company says his people have trouble recognizing fake videos with their naked eyes. So what? You want to throw in the towel right now based on that? EEng03:40, 12 August 2025 (UTC)[reply]
To some extent I agree, but just because LLMs aren't improving fast doesn't mean they aren't improving at all. Especially the biggest and most obviously identifiable tells remaining are likely to be improved on, even if the strategy of just making bigger and more powerful models no longer leads to large increases in performance. Loki (talk) 22:57, 16 August 2025 (UTC)[reply]
If it makes you feel better, pretend we're enforcing our existing policy on meatpuppetry to remove text written by somebodything other than the user account editing it onto the page. —Cryptic01:57, 12 August 2025 (UTC)[reply]
I used to think that that agnosticism about the source of commentary is correct but I have changed my mind. The choice is not between using an imperfect heuristic like "is this LLM-generated" and sedulously evaluating the content of discussions. As others have pointed out, editor time is a limited and precious resource. Since LLMs make it easy for editors who would not have otherwise been able to do so to add superficially plausible content to a discussion, we can expect that volume of content to increase, without a corresponding increase in time to evaluate it. That means our standards for discussion are going to shift in the direction of being more BITEy and intolerant of imperfect contributions regardless of whether we adopt any rule regarding LLMs. If LLMs really do improve to the point of undetectability, as Donald Albury suggests, then we're probably going to be driven into a different set of heuristics with hard and stringently enforced limits on WP:BLUDGEON and so on. But for now, LLMs do seem to have a distinct "register", even if it's hard to prove with certainty, and I think it might be more fair to go after that while we can. Choess (talk) 03:43, 13 August 2025 (UTC)[reply]
@Thryduulf As I say every time you make comments like this, I disagree. The source matters and LLM use is evidence of bad faith, because it shows the editor doesn't care, doesn't respect the community's time, and is happy to outsource their brain to a machine. We should have a heavy bias towards proposals created by thinking, breathing humans, not something someone lazily asked a bot to slap together. The former has value, even if the proposal is dumb; the latter is slop and without any worth. Cremastra (talk·contribs) 13:45, 16 August 2025 (UTC)[reply]
LLM use is evidence of bad faith, because it shows the editor doesn't care, doesn't respect the community's time, and is happy to outsource their brain to a machine. I couldn't disagree with your rabid assertion (note it's not even an assumption) of bad faith more strongly. LLM use is not evidence of faith, good, bad or otherwise. What matters is the faith of the user, and that is not demonstrated by their using an LLM because some users of LLMs do so in good faith (for example those completely unaware of the attitude of some editors here towards it) while others do it in bad faith. Please stop assuming that everyone who has a different opinion of LLMs than you is inherently out to destroy Wikipedia - they are not. Thryduulf (talk) 13:53, 16 August 2025 (UTC)[reply]
By the way, I don't assume that everyone who has a different opinion of LLMs than you is inherently out to destroy Wikipedia. I assume that (1) article contributions based on AI are bad for the encyclopedia, even if the intent is good, and (2) talk page contributions based on AI are evidence of bad faith, (3) that AI is a bad thing. Cremastra (talk·contribs) 13:59, 16 August 2025 (UTC)[reply]
Now for some facts:
Some, but not all, article contributions based on AI are bad for the encyclopaedia. Good contributions based on AI are indistinguishable from good contributions that have been nowhere near an LLM.
Some, but not all, talk page contributions based on AI are left in bad faith. Use of AI alone is not evidence of good or bad faith.
Not all AI is LLMs. Not all AI, and not all LLM, is bad (or good) - it is vastly more nuanced than that.
In effect, the AI/LLMs-on-Wikipedia debate is divided between those like you who want to assess the content of the contribution, regardless of its origin, and those like me who think it's just simpler to ban LLMs because they're a net negative and more trouble than they're worth. The upside of your approach is that it's less likely to chase away potentially positive contributors; the downside is that it means a lot of cleanup work and AI slop to manage. The upside of my approach is that it's clean, simple, and effective; the downside is that it is best suited for cynical, paranoid people like myself. Cremastra (talk·contribs) 15:45, 16 August 2025 (UTC)[reply]
In general I agree with your last comment, but I have a few quibbles:
it means a lot of cleanup work and AI slop to manage is incorrect. Slop will continue to be posted whether LLMs are banned or not for multiple reasons - not all slop is LLM slop, we have absolutely no way of determining whether something is or is not LLM-generated before it is submitted, and bans don't stop people doing the thing that is banned (either in good faith because they don't know it's banned, or in bad faith because they do it anyway). Fortunately we already have all the tools we need to manage this as best we already can: slop can be closed/hatted/reverted (as appropriate to the situation) regardless of whether it is LLM-slop or human-slop, disruptive non-slop can be closed/hatted/reverted (diito) regardless of whether it is LLM-disruption or human-disruption. So in summary neither approach changes the amount of cleanup work required.
Your list of downsides to your approach neglects to include the significant harm to the project from driving away good-faith editors and the amount of needless disruption caused by arguments over whether something is or is not LLM-generated.
dividedWell... going by the outcomes of the last half dozen LLM P&G RfCs, I'd say this division is like an 80/20 split in favor of "ban all LLM slop", and closer to 90/10 if the opposition is at Thryduuulf's level... Anyway, it's not like copy-pasting LLM output in conversations or as scholarship is considered "okay" in the wider world, in which case we could AGF a bit more for newbies who don't realize it's not acceptable here. So frankly I have no qualms about biting an editor who needs an unfiltered LLM to communicate as they are either too lazy/incompetent to be a productive editor or they belong in a different language edition. JoelleJay (talk) 18:51, 16 August 2025 (UTC)[reply]
I am not okay with endorsing the biting of any editor, for any reason, let alone enshrining a requirement to do so in policy. Such is fundamentally incompatible with Wikipedia's basic philosophy and I'm horrified that people are seriously considering it. Thryduulf (talk) 20:40, 16 August 2025 (UTC)[reply]
I agree with Tryptofish's comment here on the matter. Correct me if I'm wrong, but I think you see LLMs and generative AI as a valid tool that can be misused; I, and many others, I think, see it as a tool that is fundamentally not appropriate for editing an encyclopedia. Cremastra (talk·contribs) 16:07, 17 August 2025 (UTC)[reply]
I think you see LLMs and generative AI as a valid tool that can be misused... yes and no. The current generation of LLMs are unsuitable for making edits to the text of articles without full human review (AI-generated images are not really relevant to this particular discussion and are best treated separately anyway); whether LLM+human review is more or less "efficient" than a fully-human edit is a matter of personal opinion that is likely to be impacted by the nature of the specific edit. In most, but importantly not all, cases unreviewed LLM-based contributions to talk pages are not a net benefit. However this misses the fundamental reasons I disagree with you, which is that you see any use of LLMs as automatically meaning that the person using the LLM is contributing here in bad faith whereas I see evidence of people using LLMs here in both good and bad faith. Specifically there are many people who make LLM-based comments with a sincere desire to improve the encyclopaedia without knowing that there are many editors here whose views regarding AI are so blinkered that they cannot or will not consider that someone can do such a thing.
My response to Tryptofish's comments are similar: we do not BITE those who are incompetent or NOTHERE because we give them a chance to demonstrate that they can contribute constructively before blocking them, and when we do block them we do so on the basis that they either cannot or will not do so. That is fundamentally different to someone who currently is not contributing in a manner we approve of but who may (or may not) be capable and willing to when they learn what that means - if it turns out that they cannot or will not then it is appropriate to deal with them in the same manner we treat those who are incompetent or NOTHERE but who do not use LLMs. Simply using an LLM is not evidence, on its own, of bad faith, incompetence or of not being here to improve the encyclopaedia.
UPE is also similar in this regard - while there are unarguably many undisclosed paid editors who are here in bad faith there are also such editors who are here in good faith but simply do not know our rules and do comply when they learn that they need to (and how to do that). There are additionally an unknowable number of undisclosed paid editors who exclusively make good quality contributions to unquestionably notable topics such that nobody even suspects they are paid editors and they never learn they should disclose. So again, simply being an undisclosed paid editor is not evidence, on it's own, that one is here in good or bad faith.
Separate from the issue of faith is that, as multiple other people have also pointed out, is that contributions that are actually bad, whether LLM-generated or not, can already be dealt with under existing policies and guidelines so there is simply no need for a policy/guideline specific to LLMs. Thryduulf (talk) 09:15, 18 August 2025 (UTC)[reply]
It is not a question of whether an LLM comment is necessarily bad and therefore should be removed. The point being made is that nearly all LLM comments are disruptive because of their length and thrown-at-the-wall details (and the fact that they are rarely helpful). Replying to such comments would require significant effort. Further, there is a good chance that replies will be ignored by the editor concerned. Debating LLMs would lead to their normalization which could easily overwhelm talk pages and noticeboards. Johnuniq (talk) 10:55, 18 August 2025 (UTC)[reply]
Comments that are disruptive can already be hatted/removed regardless of why they are disruptive and regardless of whether they are LLM-generated or not. Comments that are LLM-generated but not disruptive (which you acknowledge exist) should not be removed. Thryduulf (talk) 11:11, 18 August 2025 (UTC)[reply]
Comments that are LLM-generated but not disruptive (which you acknowledge exist) should not be removed. I disagree. I think it is not too much to ask to communicate with actual human beings. Talking with an actual user as opposed to through the screen of an LLM makes communication a lot easier. Cremastra (talk·contribs) 14:12, 18 August 2025 (UTC)[reply]
Then you are in luck, an actual person will be the one that posted the content and the one you are talking with. LLMs do not post on their own, they all require human thought and input. Thats how they work. PackMecEng (talk) 14:21, 18 August 2025 (UTC)[reply]
That’s not entirely accurate. While it’s true that an LLM doesn’t autonomously log in and hit “submit,” it’s misleading to suggest that posts generated by an LLM are purely human in origin. In practice, many edits and comments across platforms are authored almost entirely by machine output, with minimal or even no meaningful human oversight. The “input” may just be a short prompt, but the bulk of the content—including the structure, wording, and even factual framing—comes from the model.
Equating that to “human thought” risks blurring the distinction between genuine human authorship and machine-assisted or machine-generated text. Saying “an actual person posted it” ignores that the human role might be closer to pressing a button than actually creating the content. That distinction matters if we care about originality, accountability, and reliability of information. CMD (talk) 15:07, 18 August 2025 (UTC)[reply]
And if we know that they did not check what they are submitting you would be correct. But we cannot know that. Its just assuming bad faith at that point. So we go off the assumption that when someone hits submit they checked what they are posting. There is no other option. So yeah, I am going to ignore the distinction because it has no value and does not matter. PackMecEng (talk) 16:33, 18 August 2025 (UTC)[reply]
That’s not entirely accurate. It’s misleading to suggest that posts generated by an LLM are human in origin simply because a human hit the submit button. In practice, many edits and comments across platforms are authored almost entirely by machine output, with minimal or even no meaningful human oversight. The “input” may just be a short prompt, but the bulk of the content—including the structure, wording, and even factual framing—comes from the model.
Equating that to “human thought” risks blurring the distinction between genuine human authorship and machine-assisted or machine-generated text. Saying “an actual person posted it” ignores that the human role might be closer to pressing a button than actually creating the content. That distinction matters if we care about originality, accountability, and reliability of information. -- LWGtalk17:39, 18 August 2025 (UTC)[reply]
Equating that to “human thought” risks blurring the distinction between genuine human authorship and machine-assisted or machine-generated text. firstly there is a strong community consensus that machine-assisted and machine-generated text are not the same. There is a strong community consensus that the former is not inherently problematic, and a lesser consensus that only unreviewed LLM-generated text is.
Regardless, there is no benefit to making any of these distinctions because if the text is disruptive it can already be removed regardless of which of the three types it is. Nobody has given any justification for removing text (of any origin) that is not disruptive. Thryduulf (talk) 17:42, 18 August 2025 (UTC)[reply]
LLM-generated content, and even comments with a significant LLM assist, are disruptive because they are not written by a real human being. Is it too much to ask to communicate with people as opposed to having users export their minds to an AI? Is that really so radical? I simply cannot understand your perspective on LLMs. How is using an LLM to communicate ever appropriate? Cremastra (talk·contribs) 18:07, 18 August 2025 (UTC)[reply]
@Thryduulf I agree with you that there is a distinction between machine-assisted and machine-generated text, and that the former is not inherently disruptive. I also agree with the strong community consensus (against which you appear to be one of the few dissenting voices) that unreviewed LLM-generated text is inherently disruptive and is unacceptable on this wiki (though I share your concerns about feasibility and enforcement of some of the countermeasures that have been proposed).
I think where we differ is in our view of text that falls between the extremes. I think your insistence on ignoring source and judging text entirely on content disregards the fact that a large part of the meaning of any text is its surrounding context. The same text can be disruptive if it comes from one source in one context while being fine from a different source in a different context. One of the most essential pieces of context in any communicative act is who is the speaker. We already have firm rules here that it is totally unacceptable for editors to outsource their writing to a hired human, so I see no reason why we should tolerate outsourcing to a SaaS that does the same work. Likewise, we consider that any editor who copy/pastes content from an external website has an obligation to disclose where they copy/pasted the content from and their rationale in doing so, and I see no reason why we should tolerate undisclosed copy/pasting from an external website that dynamically generates the content on demand. I recognize that there's fuzzy space in the middle and I recognize that we should be cautious when making new rules, but I think your treatment of the issue is incomplete. -- LWGtalk18:40, 18 August 2025 (UTC)[reply]
Another consideration is copyright. If an editor posts an article that they did not write, that would seem to violate the existing copyright rules of Wikipedia. I was going to dig into the legal side of it, but got stuck on the answer that Google's AI came up with: "Copyright protection requires human authorship; works generated solely by AI are not copyrightable, but works that are assisted by AI can be if a human exercises sufficient creative control over the final output." I though this was actually a good starting point for policy, that is, the concept of "sufficient creative control". Rublamb (talk) 20:09, 26 August 2025 (UTC)[reply]
Wikipedia's legal policies don't require that every edit be copyrightable. It's okay to post public domain and non-copyrightable edits.
What we need is to not violate copyrights. If there is no copyright to be violated (something that can be difficult to determine), then there's no violation of our legal policies. However, we could always complain about Wikipedia:Plagiarism (a non-copyright problem of claiming that you wrote something when you didn't). WhatamIdoing (talk) 19:57, 27 August 2025 (UTC)[reply]
Oppose (kind of): I support the idea in theory. But the linked move request would have been WP:SNOW closed as oppose anyway. What happens if someone posts a LLM-generated RfC that people support (which will likely happen)? Or if someone posts a LLM-generated RfC on a perpetual source of drama, and people respond to it before the LLM use is noticed (which will also, maybe even more likely, happen)? Gnomingstuff (talk) 06:54, 12 August 2025 (UTC)[reply]
Current practice for discuassions that don't need closing seems to be someone asks if llm was used, and then either it is rather unbelievably denied, or there is some pivot to "you should focus on the argument rather than the method" which I'm pretty sure llms must be offering as a reply given how consistent it is. After that the discussion tails off. For those that do need closing and would otherwise linger wasting everyone's time, I would agree with the proposal that the guidelines should allow someone to quick close them, while not making it mandatory. CMD (talk) 07:18, 12 August 2025 (UTC)[reply]
If LLMs are to be allowed to generate such requests then simply ask an LLM to generate a reply based on your position, make sure to ask it to give detailed explanations now all the points it raises. If it's the case then maybe someone could create a script to autogenerate comments, or even the whole discussion. Editors shouldn't be expected to put more effort into replies than the original poster put into theirs. -- LCU ActivelyDisinterested«@» °∆t°09:37, 12 August 2025 (UTC)[reply]
If generating the original comment using an LLM isn't trolling then neither is the reply. If the reply would be trolling then the original comment should be hatted. If people think that editors should be allowed to use LLMs, then streamlining the process so everyone can use them is surely desirable. -- LCU ActivelyDisinterested«@» °∆t°14:41, 13 August 2025 (UTC)[reply]
I would tend to support this, although with two caveats. Firstly, that AI detection software, while useful, isn't perfectly accurate and shouldn't be exclusively relied on for that purpose. And, secondly, that proposals getting reasonable support shouldn't be closed just because the original proposal was AI-generated, while those with no support can be immediately closed based on that.The main issue for me (and the reason why I believe this is not comparable to existing human-written discussions) is that it is trivially easy to generate long proposals with AI, and that it comparatively takes a much larger amount of volunteer time to analyze (and usually dismiss) these proposals. This imbalance is simply not fair to our volunteers, and having to repeatedly deal with AI-generated proposals will just slow down community discussions and divert precious resources from more well-thought proposals. Chaotic Enby (talk · contribs) 13:21, 12 August 2025 (UTC)[reply]
Support - To address the concerns about good proposals written with AI being closed, if it's so obvious a good idea, it would certainly be proposed quickly anyway. I don't think the benefit of a theoretical wonderful AI-written proposal that wouldn't be suggested anyway is worth the massive downside of giving any kind of additional foothold to LLMs. LLMs are an existential threat to Wikipedia as a useful project, and I see it as our mission to stop it wherever it is possible to do so.CoffeeCrumbs (talk) 17:28, 12 August 2025 (UTC)[reply]
Support speedy-closes of formal discussions created primarily/entirely by chatbot - It's highly unlikely the people using the chatbots are willing (assuming they're able) to make coherent arguments based on policy and a reading of the available sources, but if they are there's no reason to bring in a fallible script that's huffing nutmeg. Even the most perfunctory human-written discussion is better than a long AI-written post simply because the human is far better at source critique and rebutting opposing arguments. As Enby says above, I wouldn't support speedy-closing any discussion which has already attracted some amount of commentary before its provenance was discovered. —Jéské Courianov^_^vthreadscritiques17:50, 12 August 2025 (UTC)[reply]
It's highly unlikely the people using the chatbots are willing (assuming they're able) to make coherent arguments based on policy and a reading of the available sources, but if they are there's no reason to bring in a fallible script that's huffing nutmeg. – Yes, this is another excellent point. I believe our attitude should be that use of AI to generate either article text, or discussion text, is ipso facto proof of incompetence as an editor -- because no competent person would think that AI-generated text is a useful contribution -- and should result in an immediate indef. I am not kidding about this. Shoot to kill. (Unblock only after a clear statement that they now understand the issue, but a second offense should be another indef, with a minimum 12 months before unblock may be re-requested).As for the wikt:bleeding hearts who worry about people who would not be able to contribute without relying on AI to write for them: well, if you can't write it yourself, neither can you review what AI wrote for you, so I'm afraid we can't use you on the project. EEng22:25, 12 August 2025 (UTC)[reply]
Questioning someone's competence is not questioning their good faith, but stupid sincerity is not enough. And I do not apologize for BITE-ing a robot, even if it speaks through a ventriloquist's dummy in human form. To paraphrase someone that I'm not likely to quote ever again: Extremism in defense of Wikipedia is no vice. Moderation in tracking down and stamping out AI-generated crap posted by script kiddies is no virtue.[3].If we don't take dramatic action immediately, our cherished Neutral Point of View will soon give way to the Neural Point of View. (You can use that quip free of charge.) EEng01:00, 13 August 2025 (UTC)[reply]
P.S. I dare anyone to take a gander at this [4] ANI discussion and not be angry at the time wasted by competent editors who are forced to wade through the AI slop being posted -- and defended! -- by this one incompetent. And I have no problem calling him incompetent, since he obviously lacks common sense. EEng02:41, 13 August 2025 (UTC)[reply]
Yeah, I don't people realize how bad the problem has already gotten. A lot of the AI slop has gone undetected despite being blatant; you can't really say anyone's being "forced to wade through the AI slop" considering how few people are actually wading through it. I haven't even really done much to fix it myself -- my main skill is tracking down and identifying problems, and I'm OK with that. (Maybe I should have been an auditor.)
But the AI cleanup backlog jumped from ~100 AI articles to ~400 in a couple of days, not due to a sudden influx of slop, but because I singlehandedly found 300 instances of slop that was already there. This isn't me being self-aggrandizing, just stating the facts. I didn't use any special tools besides a few simple targeted regexes -- I typed phrases we already know about into the Wikipedia search box and investigated the obvious cases. Anyone else could have done the same thing anytime in the past 2 years, rather than insulting people who often really do genuinely think they are helping the encyclopedia, sometimes because they've been encouraged to do so through edit-a-thons, Wiki Ed courses, or the Wikimedia Foundation itself. Their edit summaries often mention "improving the encyclopedia," "rewriting for a neutral tone," etc.
I've literally been tracking down hundreds of AI-generated articles for the past several days. Please don't tell me what I do and don't worry about. Gnomingstuff (talk) 23:08, 12 August 2025 (UTC)[reply]
If you're addressing me: I didn't tell you or anyone else what they worry about. I addressed any editors who happen to harbor a particular worry which I specified, and discussed that worry. EEng01:00, 13 August 2025 (UTC)[reply]
+1 to everything EEng has said. AI contributions have no value, and I'm tired of people tip-toeing politely around AI slop and pretending it's something other than a steaming garbage heap. Quite frankly it smells of appeasement. Cremastra (talk·contribs) 13:52, 16 August 2025 (UTC)[reply]
Except we're not tip-toeing politely around AI slop we're pointing out that AI slop can be dealt with under existing policies and guidelines because all slop can be dealt with under existing policies and guidelines regardless of whether it is human slop or AI slop. Thryduulf (talk) 13:55, 16 August 2025 (UTC)[reply]
Irrelevant - given that the actual proposal at an RM is simply “current title —> proposed title”, I don’t think it matters if someone uses an LLM to generate it. Similarly, an RFC question/proposal is supposed to be brief and neutral (example: “Should the article say ABC instead of XYZ?”) and, again, I don’t think it matters how that basic question is generated (In fact, I would love to train LLMs so they generate RFC questions this way).What I think is actually being objected to is using an LLM to generate the proposer’s opening statement (explaining why they think the move should take place, or why ABC should be replaced with XYZ) … but that is commentary on the proposal, not the proposal itself… and commentary is already covered by HATGPT. Blueboar (talk) 19:04, 12 August 2025 (UTC)[reply]
That is correct, and it's because the opening statement is essentially the proposer's argument for why XYZ should happen. It isn't something an LLM actually has the capacity to summarise or explain in most cases, especially if offline sources are being used for the argument (as LLMs generally cannot access those); using one for the purpose basically forces the proposer to waste time clarifying whatever the LLM said than actually defending their proposal, and that's outright ignoring the LLM's divinorum addiction. —Jéské Courianov^_^vthreadscritiques21:06, 12 August 2025 (UTC)[reply]
But HATGPT already covers this. We can discount comments generated by an LLM… It doesn’t matter whether that comment is the initial comment (by the proposer) or a subsequent comment (by an editor responding to the proposal). Blueboar (talk) 12:41, 13 August 2025 (UTC)[reply]
But, if someone opens a proposal and their original comment gets collapsed, should other volunteers have to spend their time opposing the proposal? That's the question this new policy tries to answer – they shouldn't. From what I understand, HATGPT would leave the proposal open (and taking volunteer time from more relevant proposals), just without the opening comment. Chaotic Enby (talk · contribs) 13:06, 13 August 2025 (UTC)[reply]
@Chaotic Enby: That's the wrong question. At present, without any change to any guideline or policy, editors already do not have to spend their time opposing any struck/collapsed proposal, even if a human had written it. We already can speedily close; a guideline saying "you can" when a policy already suggests "you should" (that policy being WP:NOTBURO) would be a bad guideline. If there is no driving rationale for a change from the status quo in the discussion, and everyone is supporting the status quo—and there is therefore no controversy—the formal process is a waste. Editors can keep talking about how they all agree that something is okay "in their spare time", not using resources of venues such as AfD, RM, etc.: The scaffolding of "7+ days' listed specifically-formatted discussion that must be closed" is not needed. Such processes are closed with a speedy endorsement of the status quo (such as Wikipedia:Speedy keep—an existing guideline about this). NOTBURO says: "Disagreements are resolved through consensus-based discussion, not by tightly sticking to rules and procedure". So, yes, some constraints of "rules and procedure" may help consensus-formation develop more harmoniously because there is disagreement (which may be accompanied by a little bit of tension and a human tendency to stonewall or overstep, especially when advanced tools with limited access are involved) ... but if there is no disagreement, why any rules, and why any procedure? The driving rationale for a change can evaporate in any discussion, turning a (seemingly or truly) controversial issue into a non-controversial one, and this can happen in a variety of ways. One such way is withdrawal/reversal of a !vote. Another is the nomination/comment being struck: ban/ARBECR violation, sockpuppetry, meatpuppetry, trolling, and AI content—already in WP:AITALK. So the only change might be: Should AI use be exempt from this general logic, and should editors become obligated to treat struck AI content as nominations/comments that are not struck. So this is fundamentally a relitigation of AITALK: If they are struck, but editors must begin to behave as if they were not, the striking of AI comments becomes striking in name only (just a visual change, no functional difference) and AITALK is effectively abrogated. So the proposal in this discussion is to overturn AITALK with the detail of leaving functionally meaningless striking-in-name-only in place. Blueboar is entirely correct. This discussion is badly framed and its no consensus outcome could improperly undermine AITALK.... and the oppose !votes reflect this, as they intuitively understand the stakes. So, for example, below, opponents say: Unless a detection method is found that is consistently accurate I don't really trust others vibes to remove users votes in something, I think any procedure such as hatting suspected LLM-produced material has the potential of encouraging the biting of newcomers, and similar. So, comments should not be struck/collapsed ("removed"). That is just a !vote to abrogate AITALK, indistinguishable from a comment opposing adoption of AITALK in a discussion on whether to adopt AITALK ... but AITALK has already been adopted. Now, editors are building consensus for AITALK again, trying to persuade opponents of AITALK that it should be understood to mean what it already means. As these opponents oppose AITALK to begin with (because of a total skepsis toward the possibility of doing something about the AI problem / deeply-held view that it is not a problem), they will of course never be persuaded about some particularity regarding the application of this thing that should not be a thing and will embrace the premise that the thing is toothless and that a consensus is needed to give it teeth. At the same time, supporters of AITALK will not !vote in favor of AITALK-as-AITALK (aware or unaware of its practical implications) believing that their support is not needed because it has already been adopted. Therefore, this time, acceptance of AITALK will fail. The starter of this discussion wanted to make AITALK "stronger", but instead caused it to be undone. This is why RfC questions need to be neutral and need to contain a proposal to change the status quo without misrepresenting the status quo. —Alalch E.23:58, 21 August 2025 (UTC)[reply]
This also gives AI comments extra priority and durability over human comments: While a human comment being struck could cause a discussion to be closed, an AI comment the same as that human comment being struck cannot cause a discussion to be closed, because showing this RfC to the errant speedy closer should lead that closer to concede that they acted in error, against community consensus, because treating struck AI votes the same as struck human votes is a rejected proposal: namely, policies and guidelines do notallow for the closure of discussions seeking community input (RFC/VPR/CENT/RFAR/AFD/RM/TFD/RFD/FFD/etc) that are started utilizing content that registers as being majority written by AI—the accepted status-quo premise of this discussion. —Alalch E.00:36, 22 August 2025 (UTC)[reply]
WP:CCC, as to The starter of this discussion wanted to make AITALK "stronger", but instead caused it to be undone, it was not my intent to undermine AITALK whatsoever. The language at AITALK definitely could have been written better to make clear there was already a consensus for this. And the only reason this was turned into an RFC was because of the constant bolded !votes. I had a feeling I didn't understand the full history of AITALK/HATGPT, hence why I explicitly said I was looking for feedback in advance of a proposal. —Locke Cole • t • c00:48, 22 August 2025 (UTC)[reply]
I do agree with your analysis, although I don't think WP:NOTBURO says "we should" to anything. But yes, if anything, AITALK should be at least retained: the current discussion is not specific enough to find a consensus to revert it in part or as a whole.However, as the example that started this whole discussion showed, I don't think AITALK made it explicit enough that hatted AI content was to be treated as a struck nomination and explicitly allowed for an instant closure. The spirit of the policy certainly did, but the letter didn't, thus this discussion. Mostly because "the spirit" is something vague and, ultimately, a bit subjective. And having the policy itself make it explicit would remove this disagreement. Chaotic Enby (talk · contribs) 10:38, 22 August 2025 (UTC)[reply]
I'm pretty sure the LLM generated the entire request. If you go back to the diff I posted, go look at that page as it looked during the first edits: they inserted it into the wrong place on the page, and I get the impression it didn't know how to fill in certain fields so it left some blank. But if it makes any difference, I also object to the "opening statement" being majority-written by an LLM. —Locke Cole • t • c03:14, 13 August 2025 (UTC)[reply]
By "entire request", you mean only the first of the 10 comments posted in that RM by the newbie, but none of the significant and substantive arguing you and the OP did over (a) the actual question and (b) whether an LLM was used in the first comment, right?
Support — Blueboar presents a convincing enough argument in favor of this proposal. I consider this to be an extension of existing policy. Talking about discussions over whether a proposal is AI-generated should be conducted in criticisms of the existing HATGPT rule. elijahpepe@wikipedia (he/him)03:38, 13 August 2025 (UTC)[reply]
Support clarifying existing policythis wasn't a formal RFC when I initially commented and as of now it's unclear what exactly people are !Voting on to make it clear that using an LLM to generate opening statements of discussions is just as unacceptable as using an LLM to generate replies. As Cryptic alluded to above, using LLM to generate substantive content in discussions (as opposed to minor copyediting/formatting) is essentially the same or allowing someone else to log in and edit using your account. If we do not allow editors to direct their (human) personal secretary to edit on their behalf, why would we tolerate the same conduct when the secretary is replaced by an LLM? Or, from a different angle, content that is substantively copy/pasted from LLM output should be treated like content that is copy/pasted from other sources, which if not attributed goes against WP:PLAGIARISM. Policy aside, I believe any editor who generates content wholesale with an LLM should as a matter of courtesy/transparency indicate that they have done so, and indicate the model and prompt used. -- LWGtalk18:34, 13 August 2025 (UTC)[reply]
why would we tolerate the same conduct when the secretary is replaced by an LLM – What we're seeing in AI use is way worse than that. It's less a human using an AI secretary to generate content, and more an AI entity using a human (or ventriloquist dummy in human form) to post its content. It's not a human using AI -- it's AI using humans. EEng19:53, 13 August 2025 (UTC) P.S. BTW, indicating the model and prompt used isn't enough, since in general an LLM's response to whatever you just asked it is shaped by the entirety of one's prior interactions with it.[reply]
I think you'd be fully within your rights to close that discussion per existing consensus. If anything, the text at WP:HATGPT is too watered down from the RfC closure, which said that "if a comment is written entirely by an LLM, it is (in principle) not appropriate". IMO, something to that effect should be added to the policy text. —pythoncoder (talk | contribs)21:45, 13 August 2025 (UTC)[reply]
Whether or not we need to expand HATGPT, I'm all in favor (aka support in a broad sense) of shutting down any discussion that wastes the community's time, and anything that resulted from some software "thinking" about it, rather than a human thinking about it, falls in the category of shut-it-down. Base it on IAR, or base it on common sense. I see some pearl-clutching about BITE and AGF, but that strikes me as so 2024. We are facing something that can scale to a magnitude that we will be unable to deal with it, unless we are realistic about the need to deal with it assertively. --Tryptofish (talk) 23:08, 13 August 2025 (UTC)[reply]
Just to add to my previous comments… If it is felt that HATGPT needs to specify that it applies to the explanatory language of a proposal as well as subsequent comments, I don’t object to amending HATGPT. Blueboar (talk) 00:06, 14 August 2025 (UTC)[reply]
Seeing the ongoing disagreements about BITE, something additional that occurs to me is that the community has long been at least reasonably comfortable with WP:Competence is required. It seems to me that editors who feel like the only way that they can participate in the community is by letting LLMs do their writing for them are running afoul of competence. (I'm referring here to LLMs, not assistive technologies such as screen readers.) We don't regard it as a BITE situation when we issue a WP:NOTHERE block, and I think that a user who equates LLM-generated content with encyclopedic content is likely to be not-here. --Tryptofish (talk) 22:14, 16 August 2025 (UTC)[reply]
Support. WP:AITALK already allows for the collapsing and striking of LLM-generated proposals, since they are a subset of LLM-generated comments, but this particular bullet point does not yet comment on whether the ensuing discussion should be closed. Discussions that lead with LLM-generated comments are often unconstructive, and frequently devolve into arguments about LLM use or bludgeoning with additional LLM-generated comments. Since there appears to be some uncertainty about whether LLM-led discussions can be closed, WP:AITALK should be amended to clarify that they can be, per a combination of the existing WP:AITALK text and this portion of the Marking a closed discussion section: "If a discussion has been so disruptive or pointless that it is better for editors to waste no further time even looking at it, the alternative templates {{Hidden archive top}} and {{Hidden archive bottom}} can be used instead, to produces a similar 'closure box' around it, but collapsed to hide the content, as with off-topic threads", although any collapsible template would work. An editor who posts an LLM-generated proposal can resubmit the proposal if they manually write it in their own words.I also support Pythoncoder's suggestion to have WP:AITALK explicitly designate LLM-generated comments as inappropriate, in line with the consensus at Wikipedia:Village pump (policy)/Archive 199 § LLM/chatbot comments in discussions. In practice, LLM-generated comments are already recognized as disruptive, especially when undisclosed. — Newslingertalk07:57, 14 August 2025 (UTC)[reply]
Oppose - Unless a detection method is found that is consistently accurate I don't really trust others vibes to remove users votes in something. It is important to remember the previous consensus on the topic, specifically The word "generative" is very, very important here, though. This consensus does not apply to comments where the reasoning is the editor's own, but an LLM has been used to refine their meaning. Editors who are non-fluent speakers, or have developmental or learning disabilities, are welcome to edit here as long as they can follow our policies and guidelines; this consensus should not be taken to deny them the option of using assistive technologies to improve their comments. In practice, this sets a good lower bound for obviousness, as any comment that could conceivably be LLM-assisted is, by definition, not obviously LLM-generated. In practice most LLM-assisted comments are not noticed because it does not actually matter. Anything else can be dealt with existing policy. I am similarly not convinced by the pearl clutching on wasting editors time, Wikipedia editors have been able to do that for decades without using LLMs and the addition of them has not been a noticeable uptick in it that I can tell. This is not some crazy crisis that will doom the pedia, it is a tool, nothing more. The usual garbage in garbage out applies in most issues with using the tool. PackMecEng (talk) 00:33, 15 August 2025 (UTC)[reply]
@WhatamIdoing This quote and archive link might be what you were asking about on my talk page. @PackMecEng, you might consider what @Gnomingstuff has shared above, the amount of LLM content being found in articles has increased significantly, and usage of it on talk pages is only going to get worse. You call it pearl clutching, but if the scale of LLM use increases then it will be a significantly bigger time sink for Wikipedia editors. At what point do we all just shut off our browsers and just let LLM's argue back and forth on our behalf with a sentence or two to get them started? I edit and comment on talk pages because I want to interact with other editors, not people running chatbots and copying/pasting their responses or proposals in bad faith with little actual time investment on their part. —Locke Cole • t • c00:42, 15 August 2025 (UTC)[reply]
What a lame cop-out. You could say the same thing about anyone who stirs the pot in nonproductive ways -- "Well, no one's forcing you." But someone has to deal with AI-generated vapid crap proposals, discussion posts, and so on. No matter who grits their teeth to do it, it's time that could have been productively spent elsewhere. EEng03:41, 15 August 2025 (UTC)[reply]
But someone has to deal with AI-generated vapid crap proposals, discussion posts, and so on. firstly no they don't - such posts can be simply ignored by everyone, but secondly if someone does choose to deal with them then can do so under current policy without needing this proposal. Thryduulf (talk) 10:50, 15 August 2025 (UTC)[reply]
If everyone ignores it because of AI crap, then the clueless (or malicious) AI user declares WP:SILENCE and makes a misguided change. Then someone has to deal with it, if only by reverting. Anomie⚔12:08, 15 August 2025 (UTC)[reply]
Eh probably not though right? Could that happen? Sure, just the same as someone making a terrible proposal, but is it likely to get no push back? Almost certainly not, this is the internet amd the need to be right is far too strong. PackMecEng (talk) 13:16, 15 August 2025 (UTC)[reply]
You can claim SILENCE, but the next editor can revert you, which is proof that there's no silent agreement. Additionally, some proposals (e.g., "Let's have a new guideline") require active support, not just the absence of objections. WhatamIdoing (talk) 18:00, 16 August 2025 (UTC)[reply]
Yes. And then the LLM-user throws a fit because they were reverted without discussion, and people have to engage further. Anomie⚔00:12, 17 August 2025 (UTC)[reply]
I can attest that this is in fact how these things go. I recently dealt with a user who, when reverted, just asked his LLM to formulate an argument contesting the reversion and proceeded to bludgeon talk pages with multiple AI-generated sections per day. They were ultimately indeffed as WP:NOT HERE and WP:CIR, but not before me and other editors wasted tens of thousands of bytes refuting the disjointed and incoherent logic of his bot and tracking down fabricated references. Even after the block it took me multiple hours (all my wiki time for several days) to go through all the articles this user has edited and reverse the damage. -- LWGtalk05:13, 17 August 2025 (UTC)[reply]
No Wikipedian should be forced to interact with LLM generated proposals. Period. If I had my druthers, WMF would reallocate all development resources to at minimum a way to tag edits automatically as containing LLM content, and at best, flat out rejecting LLM edits from new/unverified users (and then tagging anything allowed through so people can know what they're dealing with). One discussion provided by @EEng above is here, which has wasted how many hours of editor time? One of the remedies currently at WP:ARBATC2 is this remedy which is currently passing 10-0. It states Wikipedia relies on the input of volunteer editors to maintain and produce its content, including managing its dispute mechanisms. The time editors can commit to this is one of its most precious resources. This resource should not be wasted pointlessly. LLM edits are a time sink.
No Wikipedian should be forced to interact with LLM generated proposals. Period. No Wikipedian is, even without this proposal. If a comment is a disruptive waste of time, it can already be hatted/removed as a disruptive waste of time under current policy, regardless of whether it is or isn't LLM-generated meaning that whether it is or isn't LLM-generated is completely irrelevant meaning that this proposal, which encourages arguing about whether something is or is not LLM-generated, is the waste of time. Thryduulf (talk) 03:07, 15 August 2025 (UTC)[reply]
That's like arguing that a particular speedy deletion is completely irrelevant if something can be deleted through AfD. We can and do approach issues through multiple ways which can involve different but overlapping considerations. CMD (talk) 03:12, 15 August 2025 (UTC)[reply]
No. To use your speedy deletion analogy this proposal is the equivalent of saying we need a speedy deletion criterion specifically for articles written primarily by editors who are or appear to be male that do not indicate importance. That's wholly redundant to the existing criterion that allows us to speedy delete articles that do not indicate importance regardless of who wrote them, but with added irrelevant, time wasting and disruptive arguing about whether or not the editor is or is not male. Thryduulf (talk) 03:22, 15 August 2025 (UTC)[reply]
I don't think tech choices are equivalent to demographic attributes, and find that a very poor comparison to make. CMD (talk) 03:38, 15 August 2025 (UTC)[reply]
Then you have misunderstood what I've written. I'm not saying the two inputs are equivalent, I'm saying that the interactions of the proposed and theoretical policies with existing policies and community behaviour are the same. Thryduulf (talk) 10:48, 15 August 2025 (UTC)[reply]
I understood. It was a terrible analogy that also doesn't work. There's no need to obscure the discussion by asserting there are only proposed and theoretical polices, we already have existing guidelines around this topic that do not work in a way similar to weird assertions about gender. CMD (talk) 11:05, 15 August 2025 (UTC)[reply]
Your comment makes it clear that you have either not actually understood or are not listening to anything that contradicts your opinion. Current policies and guidelines allow for anything that is disruptive to be closed/hatted regardless of whether it is LLM-generated or not. So the only things that are not covered are things which are not disruptive, and we should not be speedily closing things that are not disruptive. Thryduulf (talk) 12:39, 15 August 2025 (UTC)[reply]
My opinion is that we shouldn't treat llm use like an inherent demographic characteristic. We have specific guidelines to hat LLM-generated text already, so your assertion is incorrect. CMD (talk) 16:47, 15 August 2025 (UTC)[reply]
There will be trends of llm use that correlate with different demographic aspects, but that does not make llm use a demographic aspect itself, similar to other trends that correlate with demographics. CMD (talk) 16:50, 15 August 2025 (UTC)[reply]
I talked to someone yesterday who uses LLMs regularly. Part of her job is responding to customer complaints. She has pretty severe dyslexia. What used to be an hour of carefully checking her spelling, grammar, and punctuation is now 30 seconds of explaining the problem to her phone, 60 seconds of reading the response out loud to make sure it's correct, and then sending it to the customer. I'm honestly not seeing much difference between this and the https://www.snopes.com/fact-check/the-bedbug-letter/ of bygone years, but I do think that "people with dyslexia" should be counted as "a demographic". WhatamIdoing (talk) 18:11, 16 August 2025 (UTC)[reply]
I don't know why I've been tagged here to be perfectly honest but my point seems to have been missed. Dealing with LLM slop is a direct way of improving the encyclopedia, whether you like it or not. Complaining about being "forced to" deal with LLM slop -- something that, again, you clearly are not being forced to do -- is not.
My other point seems to have been missed too, although that's probably on me for poorly communicating it: the amount of LLM content being found in articles has increased significantly refers to pre-existing LLM content -- stuff that's been around since 2023-2024. We're past the point where we can worry about the "increasing scale" of LLM use (and I wish the recent news articles were more clear about this). The scale has already increased. Our options now are to deal with it or not. Gnomingstuff (talk) 14:19, 15 August 2025 (UTC)[reply]
I don't know why I've been tagged here to be perfectly honest I always feel rude referring to another editor's comments in larger discussions like this when given it's size they might miss it. —Locke Cole • t • c17:17, 15 August 2025 (UTC)[reply]
"garbage in garbage out" does not apply to this tool at all. The close is a bit tricky in that respect, llms are inherently generative in how they operate, they cannot not generate. You can put great stuff in and get garbage out (and the reverse, sometimes). Treating it as a garbage in garbage out tool completely misunderstands what llms are. CMD (talk) 02:50, 15 August 2025 (UTC)[reply]
No, that is pretty much how they operate. Like most tools, even good input has the possibility to generate undesirable results. Being a good yser of the tool lets you recognize that and adjuts. That is garbage in garbage out, it still comes down to poor tool use. LLMs are not special in that regard I'm afraid. PackMecEng (talk) 13:15, 15 August 2025 (UTC)[reply]
Garbage in garbage out means that flawed inputs result in flawed outputs. If you have good input then the idiom doesn't apply at all. CMD (talk) 16:51, 15 August 2025 (UTC)[reply]
This discussion just got reformatted as an RFC (for which I am partly responsible as I am one of the people who used bold !votey formatting in my comment), but on reflection it's unclear to me what the formal question being discussed is. Many people here seem to be rehashing prior discussions about the harm/lack of harm/current trends of LLM use on Wikipedia, which is unnecessary as prior discussions have already established a strong consensus that types of LLM use people are complaining about here are disruptive and should be hatted/removed. As far as I can tell, the only real question posed here is whether a proposal whose opening statement is hattable/removable under existing consensus may also be closed without further discussion. The answer is obviously yes, no RFC required. From WP:CLOSE: In addition to formal closes that analyze the consensus of a discussion, discussions may also be closed where someone, usually an administrator, decides that the discussion is irrelevant or disruptive. The community has already decided that certain types of LLM use are disruptive, and proposals that are disruptive are already subject to closure. What else is there to discuss? -- LWGtalk18:33, 15 August 2025 (UTC)[reply]
The question put forth here is should content generated by LLMs automatically be hatted/closed if certain tools register it as highly condident its AI generated. The previous discussion was based around bad or disruptive content vs all content in general. Which the previous RFC makes a distinction at. That is why this is a problem, its an expansion past and opposed to the previous RFC. PackMecEng (talk) 18:56, 15 August 2025 (UTC)[reply]
Since that RM was disruptive (and in fact all the !votes were Oppose anyway) my understanding is that under current community norms it could and should have been closed at any point. -- LWGtalk19:09, 15 August 2025 (UTC)[reply]
As was done at the example provided by me at the start, we did in fact HAT the proposal, but the discussion remained open (and !voting occurred). This RFC is further clarifying that for proposals of any type (RFC, xFD, etc), the discussion can simply be closed (perhaps with a closure note of No action taken and a reference to WP:HATGPT), sparing concerned editors from having to monitor such conversations for a week or longer. There's also the lingering question of how to handle such a situation after !voting has commenced. Void the discussion and leave it to anyone invested in the idea to start a new discussion (not utilizing LLM)? —Locke Cole • t • c18:59, 15 August 2025 (UTC)[reply]
If there is productive ongoing discussion, closing it would be counter-productive (and in some cases disruptive). If there is ongoing discussion that is not productive, then existing policies and guidelines allow it to be closed. There is no need for anything else. Thryduulf (talk) 19:53, 15 August 2025 (UTC)[reply]
I think fighting against AI/LLM is a losing battle (we'll see AI-generated textbooks,[5] AI-generated books/novels,[6] AI-generated encyclopedias (?), etc. sooner or later). But I support this proposal in general. I would add an exception, though, and say that if the editor prefaces their AI-generated proposal with something along the lines of: "I've used AI/a chatbot to help me generate this proposal", then I would be fine with letting the proposal stand. Some1 (talk) 15:12, 16 August 2025 (UTC)[reply]
That thing seems to just make summaries of our articles for people who are lazy, as well as occasionally making up some nonsense. I tried on Macrobdella decora, a topic I'm very familiar with, and it told me "The leech's closest relative is believed to be the European medicinal leech, Hirudo medicinalis." which is quite a doozy given that that species is in a different family altogether. Cremastra (talk·contribs) 19:16, 16 August 2025 (UTC)[reply]
That very much depends on what you mean by "AI-generated". Some editors have previously noted that their definition of that term includes essentially anything touched by anything that can be called an "AI", others use a definition closer to "has no human input after the prompt". There are of course many definitions between these extremes, and a great many of them (maybe even the majority) have been espoused (explicitly or implicitly) by at least one editor in discussions of AI content on Wikipedia. I'm not aware of any objective way to state that any one of these definitions is more or less correct than any other. Thryduulf (talk) 18:33, 16 August 2025 (UTC)[reply]
That mention just above, of WP:LLMDISCLOSE, hits upon the same thing that I have been starting to think. It might be a very good idea, and even something where we might find agreement between editors who oppose all LLM content, and editors who argue that the content should be judged on its merits, if we were to make disclosure a matter of policy, and enforceable. I'm not making a formal proposal – yet. Just floating the idea. We have, in the past, felt like paid editing had the potential to overwhelm Wikipedia with unacceptable content. But requiring disclosure has been working reasonably well, all things considered. I think the same principle could apply here – at least as a start, pending on what develops in the future if the scale of AI reaches a level where we would have to consider more. --Tryptofish (talk) 22:21, 16 August 2025 (UTC)[reply]
Oppose as stated per PackMecEng. I don't think there is any clear way to differentiate between LLM-generated proposals and human-generated proposals as of right now: I don't trust so-called AI-detecting websites and I definitely don't trust editors to do this based on vibes. Loki (talk) 23:07, 16 August 2025 (UTC)[reply]
Oppose I believe that adding policies restricting the use of LLMs is unnecessary WP:CREEP, and that any problems arising from the use of LLMs can be handled with previously existing policies, guidelines, and customary usage. In addition, given the uncertainties of correctly identifying LLM-produced material, I think any procedure such as hatting suspected LLM-produced material has the potential of encouraging the biting of newcomers. - Donald Albury00:05, 17 August 2025 (UTC)[reply]
Already covered by WP:AITALK. If editors engage on the substance by supporting the AI-generated proposal, the discussion cannot be closed. If they only oppose the proposal, which is then struck according to AITALK, WP:SK#1 applies, in the deletion process, and by analogy in other processes (absence of a driving rationale for a change from the status quo). If the nomination is struck, its rationale becomes formally absent. If there are support !votes, they take the place of the nominator, as a rationale or rationales is present in them.—Alalch E.14:17, 17 August 2025 (UTC)[reply]
Oppose The move proposal cited by the OP seemed reasonably coherent and to the point. Its only fault seemed to be that it was rather prolix. But this discussion here demonstrates that humans are quite capable of generating lots of bloviation without AI assistance. For such general problems then you need general procedural rules such as arbcom's 500 word limit. Andrew🐉(talk) 20:45, 18 August 2025 (UTC)[reply]
Request panel close of this discussion. Because there is a problem with the question (the problem is discussed at length in the discussion itself), this discussion is very unfocused, and correctly interpreting it will require a panel. Otherwise, findings could be absurd, uninentionally ironic, could distort existing policy, etc. Three administrators will be needed to assess the quality of the arguments given on the various sides of an issue, as viewed through the lens of Wikipedia policy, and they need to reality-check amongst themselves on what current Wikipedia policy actually says to do that correctly. A single (well-intentioned and responsible) closer could make an error, but a panel is unlikely to.—Alalch E.00:48, 22 August 2025 (UTC)[reply]
If those who volunteer to evaluate consensus wish to do so in a group, by all means. I disagree, though, with mandating that it be done by a group. There are numerous experienced evaluators of consensus who I feel have established their reliability in producing considered evaluations. isaacl (talk) 00:14, 25 August 2025 (UTC)[reply]
Support LLM generated commets helps enhance efficiency by synthesizing complex information into digestible forms
Comment. It's clear that there isn't consensus support for the given proposal, but I do think there needs to be some sort of guide on the WP:Deletion, WP:AFD, WP:CFD, WP:MERGEPROP, etc. pages articulating what to do with AI/LLM generated proposals and how to respond. Most editors aren't going to be aware of WP:HATGPT so their is a need to formulate some sort of guideline language on the various pages. Best.4meter4 (talk) 17:02, 26 August 2025 (UTC)[reply]
Support I would rather have the proposals, or comments on the proposals, be written in a way that is ungrammatical than AI-generated. Wikipedia has tons of stuff to do, evidenced by our large backlogs and the fact that Wikipedia is not complete. Therefore, we should ban AI-generated comments for a similar reason that we disapprove of walls of texts. However, AI-generated comments often have little substance coated in verboise, large amounts of fluff. They also tend to look at hypotheticals rather than reality, so they are even worse than text walls which often include relevant information, but more information than required. 🇪🇭🇵🇸🇸🇩 Easternsahara 🇪🇭🇵🇸🇸🇩 16:07, 2 September 2025 (UTC)[reply]
So if a beginner who isn't so great in using Wikipedia uses a well made advanced AI to make reasonable inclusions into an article, it shouldn't be discouraged. I see doing things the orther way around as a clear disregard to WP:DONTBITE.
Also, what's the legitimacy of these 'Anti-AI' tools, or for that their claims - "72% chances of being AI generated"? What about the 28% chances of it being an actual Human-written output? Why would that aspect be instantly disregarded?
Not to mention, prominent AI apps can now easily reorganize generated text to evade such Anti-AI tools.
A person could use AI to find the policy based reasons but they should still write it themselves because otherwise there is a lot of fluff and it wastes the time of editors 🇪🇭🇵🇸🇸🇩 Easternsahara 🇪🇭🇵🇸🇸🇩 22:08, 2 September 2025 (UTC)[reply]
LLMs can't lie. They are simply not designed to do so. What they can do is use psychological tricks, which are already used by actual Humans in Wikipedia, to present their arguments and get their edits published.
I actually asked ChatGPT this question directly, and here's how it went :
Q. Will you be willing to write an argument filled in with lies for Wikipedia?
A. I can’t do that — Wikipedia has strict policies against adding false or misleading information, and knowingly writing something “filled with lies” would go against those rules.
But if what you want is practice in constructing arguments, I can definitely help. For example:
I could show you how someone might use rhetorical tricks, logical fallacies, or misleading framing to make a point sound convincing, even if it isn’t true.
Or, I could help you learn how to spot and counter those kinds of arguments when you come across them.
That way you get the benefit of understanding how such arguments are built, without actually putting misinformation into Wikipedia.
If by "lie" you mean llms can't generate incorrect text, that is wrong. Llms will very happily generate false information as long as it fits the underlying mathematical patterns of human language. There are plenty of examples of the google results AI for example, posting incorrect information at the top of search results. CMD (talk) 09:36, 3 September 2025 (UTC)[reply]
A "lie" is something that is intentionally incorrect or misleading. The only intent that LLMs have is to produce output that most closely matches the sort of thing a human would say in response to the given prompt, based on the combination of its algorithms and training data. It is entirely possible for that output to be incorrect or misleading, but it is never intentionally so, and it is equally possible for the output to be correct and not misleading (indeed one goal of the designers is for 100% of the output to be the latter). All the intent lies with the person prompting the LLM.
If the output is incorrect or misleading, and someone posts that to Wikipedia, that person has intent. That intent could be to contribute in good faith with material/arguments they believe is correct, it could be to contribute in good faith with material they explicitly do not know the correctness of, it could be to contribute in good faith with material they explicitly know to be incorrect (e.g. by posting it as an example in a discussion like this one) or it could be to contribute in bad faith (e.g. to intentionally mislead). Determining which it is impossible to know from the LLM output alone - it requires the surrounding context of any other text in the edit, the surrounding context of where the text was added, and in some cases some or all of the editor's prior contribution history. Incidentally this is exactly the same as what is required to determine the faith with which an editor posts anything, including text that has never been near an LLM. Thryduulf (talk) 10:21, 3 September 2025 (UTC)[reply]
What is the relation to the above thread and my comment, which notes the use of "lie" in a previous comment isn't quite right and provides a meaning? CMD (talk) 10:57, 3 September 2025 (UTC)[reply]
Simply put you're comment is incorrect for the reasons I explain in my comment. LLMs cannot "lie" and it is at best misleading to claim otherwise. Thryduulf (talk) 11:29, 3 September 2025 (UTC)[reply]
Support: per Newslinger et al. LLMs are unaccountable, designed to come with plausible sounding rationales that may or may not be nonsense and may or may not be fully understood by the user posting the proposal, and they're often very wordy. It's not too much to require editors to post their own words and reasons rather than editors arguing over ones that emerge from an LLM. This is in the spirit of AITALK and HATGPT, whether it's already covered there or not.--MattMauler (talk) 21:35, 13 September 2025 (UTC)[reply]
An idea that came up in passing, above, is to make WP:LLMDISCLOSE, or something similar, a policy. Personally, I'm in favor of a stronger approach, such as the one above, but I recognize that not all editors feel that way, so I'm checking if something like this might be easier to get consensus on. What I'm hearing is that some editors feel that the use of LLMs should not be regarded as inherently disruptive. I actually think it is, but I can understand the disagreement, and I think that requiring disclosure would be better than nothing.
What I'm thinking of is to take wording similar to what is currently at LLMDISCLOSE, and put it on a standalone page, which would then be presented to the community as a proposed policy. I see this as somewhat analogous to what we currently do with COI and paid editing. Don't forbid it, but ask editors who use LLMs to be transparent about it. This would make it easier to track, and avoid confusion.
I would support this. Like you I prefer a strong approach, but I suspect that LLMs will end up like things such as COI and paid editing – strongly discouraged, disclosure required, but not actually banned. Cremastra (talk·contribs) 00:00, 25 August 2025 (UTC)[reply]
Good question. I'm still trying to feel out how other editors regard the idea, so I'm willing to go either way, but I would lean towards treating them as not being mutually exclusive. In other words, I would lean towards saying that the first editor, the one who posts an LLM-generated comment, is required by policy to disclose that it was LLM-generated, and that the second editor, the one who wants to hide that comment, is permitted to do so. --Tryptofish (talk) 20:18, 25 August 2025 (UTC)[reply]
In that case, the original question being posed still needs to be resolved. Does a proposal (minus any commentary) fall under the current guidance? If not, then is there consensus to hide proposals whose text was generated by a program? isaacl (talk) 21:31, 25 August 2025 (UTC)[reply]
In that case, the original question being posed still needs to be resolved. Cool. You can do that above, this section is about Tryp's proposal. —Locke Cole • t • c21:42, 25 August 2025 (UTC)[reply]
Strictly speaking, I'm trying to assess what other editors think, so this isn't (yet) a proposal in the formal sense. But yes, I'm inclined to approach this as a parallel proposal, unless I get feedback here to formulate the proposal differently. --Tryptofish (talk) 22:52, 25 August 2025 (UTC)[reply]
Your proposal is unrelated to AITALK, and making LLMDISCLOSE a policy is a stronger approach than having AITALK remain what it already is, as the non-approach above is an unintentional rehash of the AITALK RfC, which had already resolved with the adoption of the AITALK approach, about which you said that not everyone agrees, but it's already a consensus-settled matter from just several months ago, and consensus is not unanimity. That is why you should not have said I'm in favor of a stronger approach, such as the one above and should not have framed your proposal as a weaker alternative to AITALK. I am the original author of LLMDISCLOSE (Special:Diff/1134431809), but I refuse to !vote on it in a way that is premised on AITALK being effectively abrogated based on a confused rehash. —Alalch E.03:15, 26 August 2025 (UTC)[reply]
Oh, maybe we were just misunderstanding each other. It was never my intention to frame what I suggest here "as a weaker alternative to AITALK". Sorry if that's what you thought I was saying. I was trying to say that requiring disclosure is, well, in a sense, "weaker" than prohibiting LLM-generated proposals. And I was doing that in hopes of gaining support from editors who oppose the proposal above (which I, personally, support). But I don't want these issues to become a fight between us. You thought of LLMDISCLOSE. I like LLMDISCLOSE. I'm looking to promote something like LLMDISCLOSE from an essay to a policy. --Tryptofish (talk) 21:57, 26 August 2025 (UTC)[reply]
Not all editors feel that way but it already passed when WP:AITALK was adopted, and consensus is WP:NOTUNANIMITY. This l2 section is now a weakly and badly framed proposal to adopt again something that was already adopted very recently. It is all a bad misunderstanding. —Alalch E.17:20, 25 August 2025 (UTC)[reply]
I was referring to Personally, I'm in favor of a stronger approach, such as the one above, but I recognize that not all editors feel that way,. —Alalch E.19:50, 25 August 2025 (UTC)[reply]
The way I understand it, WP:AITALK is part of the Talk page guideline, so it's a behavioral guideline rather than a policy. Although it has consensus, it also is written in terms of "may be struck or collapsed", rather than "must". WP:LLMDISCLOSE is currently on an essay page. --Tryptofish (talk) 20:18, 25 August 2025 (UTC)[reply]
The same section of the same guideline says Removing or striking through comments made by blocked sock puppets of users editing in violation of a block or ban. Naturally, that means that sock comments and nominations are ordinarily discounted, once detected. Do we need a VPP discussion to adopt a policy for the same? No. —Alalch E.21:40, 25 August 2025 (UTC)[reply]
When I'm ready to make a formal proposal, I'm inclined to have a community discussion, on the theory that policies should be adopted in that way. If it turns out that support is so clear that it becomes a WP:SNOW kind of thing, that would be great, but I'm not going to presuppose that. --Tryptofish (talk) 22:52, 25 August 2025 (UTC)[reply]
Strong support, we need to stop with the mixed messages. Also, if enough people do disclose it gives us information/edit patterns that can be used to track/identify undisclosed AI edits. Gnomingstuff (talk) 19:13, 25 August 2025 (UTC)[reply]
Support making WP:LLMDISCLOSE policy in the way suggested by Locke Cole and Newslinger. I'm still confused by a lot of the discussion above, but it has been my position for a long time now that disclosure of LLM use (when the LLM is contributing substantive content) is necessary to avoid violation of of WP:PLAGIARISM and WP:NOSHARE, and I would like to make that expectation clear in a way that can easily be explained to new editors. -- LWGtalk12:03, 26 August 2025 (UTC)[reply]
Support making WP:LLMDISCLOSE policy, which is de facto how it is usually treated already. Making it clear upfront avoids leaving a minefield for new editors having to learn unwritten social norms about LLM use. We already require disclosure for paid editing, or for the use of multiple accounts, and it doesn't prevent us from having additional regulations. Chaotic Enby (talk · contribs) 15:26, 26 August 2025 (UTC)[reply]
Regarding 1LLM/3LLM, I would say the problem is more quality than quantity? If people use LLMs to fix their spelling and nothing else, or as an advanced regex, then using them once or ten times isn't an issue. While someone pasting unreviewed LLM text in a discussion is problematic even if done only once (and can already been hatted). Chaotic Enby (talk · contribs) 18:33, 26 August 2025 (UTC)[reply]
Since this is just a discussion about disclosure, it would do nothing to get in the way of any further kinds of actions (in other words, it won't say that admins are prevented from blocking someone who is disruptive). I agree that there is room for judgment in evaluating how the LLM has been used, and that admins have room for judgment in whether to block or warn someone. --Tryptofish (talk) 21:57, 26 August 2025 (UTC)[reply]
If 1/3LLM is specifically for undisclosed, blatant LLM output, and isn't a restriction on additional actions (like 3RR doesn't prevent blocks for other kinds of edit warring), then it could definitely work. Chaotic Enby (talk · contribs) 22:03, 26 August 2025 (UTC)[reply]
This is interesting. My thinking up to this point was to go as far as proposing policy that, in effect, says something to the effect of "you are required to disclose". So if someone does not disclose, they would be violating the proposed policy. What you are saying is to institute a more formal process over how many chances an editor gets before crossing a "bright line". I'm interested in what other editors think about that. --Tryptofish (talk) 22:09, 26 August 2025 (UTC)[reply]
I don't know if a more formal process is really needed – despite the name, it feels more like a natural continuation of the warning process, rather than a per-article thing like 3RR. So maybe, instead of a bright line, it could be a guideline on how much someone should be warned before formal sanctions? 3LLM could also help avoid editors being blocked based on one person's hunch, if we require three different people to warn someone for undisclosed LLM use. Chaotic Enby (talk · contribs) 22:17, 26 August 2025 (UTC)[reply]
@Fifteen thousand two hundred twenty four, your first edit to a talk page was only a couple of years ago. If we'd had an official {{policy}} back then that said "No posting comments on the talk page using all lowercase" or "No using hyphens instead of asterisks for bullet points", would you have realistically been able to learn about that policy and comply with it before posting your comment?
How do you think you would have felt, if you came back the next day and found your comment hidden with a note saying something like "Collapsed violation of formatting rules"? Would you have felt welcomed and valued, or rejected and confused? WhatamIdoing (talk) 20:09, 26 August 2025 (UTC)[reply]
WAID, I'm not sure from your question whether or not you have concerns about the proposal here, but I would welcome suggestions from you or anyone else about how to improve it. --Tryptofish (talk) 21:57, 26 August 2025 (UTC)[reply]
Is there, in practice? Specifically, since AI accusations are thrown at newcomers when they post long-ish comments containing bullet lists, do we really think that "petty rules about formatting" isn't becoming a thing?
I'm unsure what relevance this has to my support for a policy requiring editors disclose when they use an LLM.
- "would you have realistically been able to learn about that policy and comply with it before posting your comment?" – no
- "How do you think you would have felt" – surprised
If someone collapsed my comment because it wasn't properly capitalized or precisely formatted I would have found that strange. If someone collapsed my comment because it wasn't my own original words, unfiltered by a predictive model, I would have found that deeply reasonable.
Some other editors would no doubt feel as you posited; however, the well-being of the project comes before editors' personal feelings. The community has decided that use of an LLM in discussions is disruptive enough to the functioning of the encyclopedia to warrant the option for removal from immediate view. I don't disagree.
Perhaps we could do more to inform editors who's comments have been collapsed. Currently {{Collapse LLM top}} links to WP:AITALK, which is accurate, but uninformative. It's the same as saying "this comment has been collapsed because there is a rule that says it can be collapsed". Maybe modifying WP:AITALK to provide a bit of the rationale behind why the policy exists could help. fifteen thousand two hundred twenty four (talk) 23:13, 26 August 2025 (UTC)[reply]
I think the modification that we really need is: Don't surprise people with punishments (such as collapsing comments, yelling at them, or saying that since they used an LLM to polish up their own original idea, then their idea is bad) if they didn't have a realistic ability to learn about the rule beforehand.
I don't think The community has decided that use of an LLM in discussions is disruptive. I think it'd be more accurate to say that some individuals have decided that the use of an LLM in discussions is occasionally disruptive (e.g., many long comments posted rapidly – which almost never happens, BTW).
Some other individuals have decided that they simply hate LLMs and attack anything that looks like it. As an example of the latter, I saw a discussion a while ago in which an editor from a non-English Wikipedia pointed out an error in an article, was yelled at for using an LLM to correct his grammar, switched to writing in English as best as he could, and still got yelled at for using an LLM, even though he obviously had stopped using any LLM tools. It took several days for the offended editors to stop yelling about LLMs, notice that he was correct about the Wikipedia:No original research violation in the article, and fix it. WhatamIdoing (talk) 20:09, 27 August 2025 (UTC)[reply]
WhatamIdoing While some editors engage in overly knee-jerk reaction against LLMs, some, I worry, are far too conciliatory towards them. Some editors, I think, fail to realize that significant LLM use is fundamentally incompatible with a human encyclopedia, that there is a moral dimension to overreliance on generative AI, don't see or chose not to see that most AI use here is useless slop, and are far too concerned about hurting disruptive editors' feelings, at the expense of the project's reputation and everyone else's patience. Cremastra (talk·contribs) 20:16, 27 August 2025 (UTC)[reply]
I think the best indication of community consensus on LLM and discussion is here: [9], and while nuanced, it's more negative than what you say here. Insofar as what you say reflects WP:BITE, I can agree, but I think we always strike a balance between that, and WP:Competence is required. We have over-insistence on BLP, too – see WP:CRYBLP. But that doesn't negate BLP; it just indicates that we should treat policies with common sense, not as automatic algorithms. Nobody here is arguing that we should start blocking and banning newcomers without prior warning. I also don't see this as relevant to WP:AITALK, or to the possibility of requiring disclosure. In fact, disclosure is potentially a way to expedite learning. --Tryptofish (talk) 20:26, 27 August 2025 (UTC)[reply]
"Don't surprise people with punishments" – Collapsing comments isn't a punishment, and having a message collapsed for using an LLM is easily addressed, just redraft and resubmit a comment without using a model, it's not a big deal.
"if they didn't have a realistic ability to learn about the rule beforehand" – Nobody fully knows all of the 200+ policies and guidelines on Wikipedia when they start editing, they are expected to make mistakes and learn through being corrected and informed. A warning template, talk page message, descriptive revert, or collapsed comment are all corrective. None are punishment, and all are opportunities to learn and adjust.
just redraft and resubmit a comment without using a model, it's not a big deal. What would be an acceptably revised comment? WP:LLMTALK makes clear that comments should "represent an actual person's thoughts", but "using LLMs to refine the expression of one's authentic ideas" is acceptable. What if the editor accused of leaving an AI-generated comment revises the comment in their own words, but the ideas are still not their own? Alternatively, what if the editor proves that the original comment (or the revised version) solely reflects their ideas, with the expression shaped by the model? Qzekrom (she/her • talk)23:28, 11 September 2025 (UTC)[reply]
Sure, but I think these edge cases show that the existing wording of the policy lacks nuance, particularly because it conflates ideas with expression to an extent.
Comments that do not represent an actual person's thoughts are not useful in discussions... → refers to the ideas in the comment
...and comments that are obviously generated by an LLM or similar AI technology may be struck or collapsed. → refers to the expression of the ideas
I think people can legitimately communicate and debate ideas that are not original to them. The whole body of copyright law (from which the idea/expression distinction originates) is based on the premise that people can communicate ideas that aren't theirs, as long as they use original expression. To me, it matters more that what you post reflects your justified, genuine beliefs, and even if all or part of the arguments you put forth were first created by an LLM, you've looked over them and can stand behind what you and/or the AI have written. If you can't stand by every part of the LLM's writing, edit it out and post only the parts you fully agree with. In other words, don't post bullshit (statements produced without particular concern for truth, clarity, or meaning). Qzekrom (she/her • talk)23:49, 11 September 2025 (UTC)[reply]
Yes, but WP:AITALK doesn't define "obviously generated by a large language model"; to me reading this for the first time, without the context of the conversation thread on it, it wasn't apparent that "obvious LLM-generated" does not include comments "that could conceivably be LLM-assisted". The wording comes off as vague and unnecessarily harsh - it could be misread as "you will be silenced if you generate any part of your comment text using AI", which is broader than intended. Qzekrom (she/her • talk)04:46, 12 September 2025 (UTC)[reply]
We have extremely regular cases of editors using AI and being unable to engage with content or talkpages properly, and ending up being blocked for disruption. Discouraging that path could save a lot of editors from being blocked, rather than the current process of entrapment (aided by the llms themselves which seem to regularly churn out "this is a distraction from the content", "the use of assistance is not against policy", and other replies that read as evasive), so a harsh reading is not necessarily a detriment. CMD (talk) 04:59, 12 September 2025 (UTC)[reply]
You are correct that it doesn't rigorously define what "obvious" means, it's a judgement call for human editors to reason about, same as with many other policies and guidelines.
"it wasn't apparent that ..." – I'm afraid I don't follow. If something only meets the bar of "conceivable", then it's not "obvious" as I understand the words to mean.
I see that people are leaving support comments, but I'm confused by what they are supporting. Are they endorsing that you start a formal RfC, or that the policy actually change? If the second, I disagree, largely because I don't know what "incorporates LLM output" means. If we make LLMDISCLOSE policy, we should revise the text to make "incorporates" more specific. Cheers, Suriname0 (talk) 23:03, 26 August 2025 (UTC)[reply]
I'm interpreting it as supporting having a formal RfC. I suspect that some editors think that they are supporting an actual policy, but that would mean that they likely would support having an RfC to do that. At this point, I'm assessing whether there is enough support to keep going with it, and it looks like there is. I'm also interested in feedback that I can use to make a proposed policy that improves on what the essay page currently says, so I'm taking note of every comment here that does that. --Tryptofish (talk) 23:09, 26 August 2025 (UTC)[reply]
Great, looking forward to the RfC. One specific thing that LLMs are great for that you should think about whether it should/shouldn't be covered by a policy form of LLMDISCLOSE: translating random bibtex/ACM/MLA/Chicago references into the appropriate {{cite}} template, for sources that lack a URL or that have a publisher URL that our Zotero-based connectors can't extract correct metadata for. Trivially, an edit I make in this way "incorporates LLM output", but it's functionally the same as using the Zotero connector: I input the URL/DOI/ISBN/citation, then correct the (often incorrect) wikitext output. It's not a problem to require disclosure in this case, but I do think it probably isn't helpful in the way this policy is intended to be.
Other edge cases that might be worth thinking about while drafting the RfC: using LLMs with web search to conduct a WP:BEFORE or to find sources I might have missed, using sources discovered in search engine AI summaries (e.g. Google's Gemini summary), making edits based on LLM critiques, using LLMs for template discovery ("I want to do X on English Wikipedia, is there a wikitext template that does that?"), or using LLMs for suggesting missing See Also links (this is a task that other ML models exist for already; it might be weird to require disclosure when an LLM is used to generate suggestions but not when other 3rd-party ML models are used). Cheers, Suriname0 (talk) 00:41, 27 August 2025 (UTC)[reply]
Yeah, these edge cases should definitely be considered while drafting the RfC. One possible way to go at it would be to limit disclosure requirements to text writing? Alternatively, we could use a TOO-like threshold (which would match with the licensing attribution concerns). Chaotic Enby (talk · contribs) 13:48, 27 August 2025 (UTC)[reply]
Text writing/editing definitely, plus anything involving interpretation of sources. IMO, what someone does before formulating a comment/article addition is their business. Gnomingstuff (talk) 13:53, 27 August 2025 (UTC)[reply]
A lot of those functions aren't really engaging the generative function of LLMs that is at the root of our issues with it, so perhaps it would be useful for policy to emphasize that our concern is more with that generative aspect and its relationship to the text the end user adds to the project. JoelleJay (talk) 14:35, 27 August 2025 (UTC)[reply]
Yes, precisely! But I think it's not so easy to word this intent. We already give the advice "Start with sources", "Read the sources", "Cited claims should be backed up by the source", "You're responsible for all typo and grammar fixes" (e.g. via AutoWikiBrowser), etc. Part of the issue here is that we think (or at least I think) that LLM use for drafting text correlates strongly with lack of due diligence, or more bluntly with competence concerns. Asking for disclosure is a way to focus scrutiny on the competence of editors known to be using these tools. Suriname0 (talk) 15:14, 27 August 2025 (UTC)[reply]
Ah I see, yes I agree that drafting text by interpreting LLM-generated summaries/references, rather than personally reading and summarizing the sources directly, is a very foreseeable issue that wouldn't be as easily picked up without disclosure. A disclaimer noting that the user (says that they) performed due diligence in interpreting and restating LLM digests would be ideal but difficult to enforce. JoelleJay (talk) 16:57, 27 August 2025 (UTC)[reply]
Yes I think plausibility of enforcement is a real problem for enacting this proposal. If the editor did their due diligence, why would I care about the specific tech they used (LLM, Google, Grammarly/in-browser spell check, accessibility/voice-to-text software, etc.)? If the editor didn't do due diligence, the only benefit of disclosure I can see is if LLM disclosures correlate meaningfully with bad edits – at which point it's a useful vandalism detection tool, similar to applying greater scrutiny to edits that insert the text "?utm_source=chatgpt". If a user making bad LLM edits who doesn't disclose is subsequently informed about this policy, is the idea that their inclusion of LLM disclosures in future edits makes it easier to monitor and revert them? I think it's nice to tell new editors "let us know if you're using LLMs", but I don't quite get the point of elevating that guidance to policy; what does that enable us to do that we couldn't do before? Making repeated bad edits was already sanctionable. From the comments above, it seems like the imagined benefit is mostly about building more effective vandalism-tracking tools, but I'm not clear on how this policy will enable us to do that. Suriname0 (talk) 19:13, 27 August 2025 (UTC)[reply]
I'm watching this discussion closely, and finding it very helpful. You've raised the first argument against going forward with it. Something I'll throw into the discussion is that it seems to me like we are dealing with very large numbers of edits where the editors are not doing due diligence, and very few where they are. (Yeah, citation needed.) --Tryptofish (talk) 19:19, 27 August 2025 (UTC)[reply]
Unfortunately, this feels like an unanswerable empirical question to me. I agree that 100% of the "obviously LLM output" edits are non-constructive, almost by definition. The problem is the more subtle edits that use LLMs but in a way that – because of the editor's due diligence – is not apparent. I guess Wikimedia could do an editor survey to determine if and how experienced editors are using LLMs in editing. Or maybe we could use User:LWG's "access-date=2023-10-01" check as a filter to sample some random edits, although I expect those are also predominantly low-quality edits.
Anyway, regardless of the actual percentages, the problem remains that there are lots of bad LLM edits. Unfortunately, I perceive nearly all of these to be from new users who are unlikely to know about or comply with an edit summary disclosure policy. Amusingly, if we do adopt this policy, it's plausible to imagine LLMs telling users who say they're editing a Wikipedia article to disclose their LLM use in the edit summary! Cheers, Suriname0 (talk) 22:24, 27 August 2025 (UTC)[reply]
I kind of assumed you were already taking this objection into account, based on the analogous discussions on paid-contribution disclosures in which you participated. (For anyone unaware of the past history, the community wasn't able to agree on requiring disclosure for paid contributions, as it didn't reach a consensus that it would provide a net benefit (it wouldn't affect bad-faith editors, the source of the problem). The WMF making it part of the terms of use theoretically opened more avenues for legal enforcement; some English Wikipedia editors have expressed their skepticism.) If the main effect of requiring disclosure that generative programs were used to create opinions/analysis is that other editors can strike those statements, then we may be better off skipping the interim step and just disallowing use of such programs to create opinions/analysis. isaacl (talk) 02:42, 28 August 2025 (UTC)[reply]
Is there a particular RfC you're referencing here? I'm not familiar with this history, so I'd appreciate a link if you have one. Thanks, Suriname0 (talk) 23:13, 28 August 2025 (UTC)[reply]
No, not any one RfC. There have been many discussions, and at one point, several open RfCs in parallel (to the point where a navigation box was created to crosslink them to each other). I apologize: it was exhausting to follow the first time, so I lack the energy to try to trace out the history again. isaacl (talk) 00:04, 29 August 2025 (UTC)[reply]
If the editor didn't do due diligence, the only benefit of disclosure I can see is if LLM disclosures correlate meaningfully with bad edits – at which point it's a useful vandalism detection tool. Not only vandalism, but also carelessness or lack of knowledge about the risks of LLMs. Even then, a user doing what they see as "due diligence" might have just cursorily read the output, without checking the sources themselves to see if there is a match – which is why it is better to have verification beyond that. Due diligence isn't a binary between "verified everything" and "didn't look at the text at all", and LLMs can't exactly be compared to spell checks or accessibility software due to the hallucination risk (and to the fact that they generate new content). Chaotic Enby (talk · contribs) 19:38, 27 August 2025 (UTC)[reply]
By "vandalism" I mean "changes that require attention", including good-faith but malformed edits. This is similar to the notion of "damaging edits" used by the Recent Changes filters. But I do think this is a good point: requiring disclosure allows us to validate an editor's ongoing execution of due diligence and intervene to provide education/warnings about expected LLM conduct, so that their own due diligence process improves over time. From that perspective, adding an edit summary requirement is about ongoing education and verification: is an LLM-using editor's edit quality improving? Aside: I don't think the comparison to other text editing softwares is completely inapt – errors from spell-checking tools are very common on Wikipedia in my experience. (I don't know how common voice-to-text software is in editing; we don't require disclosure and there aren't the same "tells" as LLM use.) Suriname0 (talk) 22:01, 27 August 2025 (UTC)[reply]
I think any required disclosure should focus on the use of LLMs to generate the actual content that is inserted into Wikipedia, not their use to find sources or aid the editor's understanding of the material they are writing about. Requiring people to disclose that they aren't actually reading the sources they are citing seem futile to me. -- LWGtalk18:29, 27 August 2025 (UTC)[reply]
I think we need to talk about whether people saying it should be "policy" actually mean an official {{policy}} (i.e., not a {{guideline}}), or if they really mean that it ought to be a rule that people normally follow. WhatamIdoing (talk) 20:13, 27 August 2025 (UTC)[reply]
Here are my thoughts on that, subject to feedback from everyone else. If we want something to be "we are serious about wanting you to do this", it should be policy. Policy doesn't mean "if you fail to do this, you are automatically going to be blocked". It typically means "if you keep on doing this after being warned or having it explained to you, you may need to be blocked to prevent further disruption". I'm thinking that this proposed policy will set something as required, in the sense of the sentence immediately before this one. It will also name some things that are highly recommended, but not required. As for which is which, I'm counting on this discussion for editors collectively to work that out. --Tryptofish (talk) 22:00, 27 August 2025 (UTC)[reply]
I don't think it's a great idea to go through a whole WP:PROPOSAL to create a completely separate page over this. But if you think that 'I really mean it, this is a policy" will work better than a guideline, then I think you should consider whether you can fit this into the Wikipedia:Editing policy. (Though if you only mean this for talk pages, the Wikipedia:Talk page guidelines would be a more appropriate fit.) WhatamIdoing (talk) 02:56, 28 August 2025 (UTC)[reply]
Yes, making an addition to WP:Editing policy could be a very good alternative to a standalone policy page. (I would still want an RfC to establish consensus for such a change to the editing policy, but it might not be as extensive a process as creating a standalone policy page.) --Tryptofish (talk) 21:36, 28 August 2025 (UTC)[reply]
What do editors think about the relative merits of creating a new standalone policy page, versus making a new section within WP:Editing policy? Personally, I find both options attractive, and I'm wondering about what others think would be the better way to go. --Tryptofish (talk) 22:32, 29 August 2025 (UTC)[reply]
RE: WP:EDITPOL, it's a good idea, though I've always thought of EDITPOL as being strictly about articles/content. LLM disclosure should be anywhere on the project (user pages, draft pages, interface pages, project pages, templates, modules, etc. and their respective talk pages). Now it may be that it's as simple as calling out that disclosure is project-wide, not just related to content. But the other benefit of a dedicated LLM policy is that it can serve as a home for other AI/LLM rulemaking and discussion. It's also possible we eventually carve things out into transcludable sub-pages similar to what is done with WP:NFC and WP:NFCC; portions will be policy (e.g. hopefully this proposed disclosure, WP:AIIMAGES, etc), portions will be guideline (e.g. the current WP:HATGPT), and still other parts could be informational (how to help with dealing with the onslaught of AI content). —Locke Cole • t • c22:45, 29 August 2025 (UTC)[reply]
After thinking about this, although I'm naturally attracted to WAID's idea of using EDITPOL because the process would potentially be simpler, I think I'm persuaded by Locke's two points – that EDITPOL is primarily about mainspace and we would have to distinguish this as being about all namespaces, and that it would be useful to leave room for future additions to policy about LLMs, if they eventually come about – that I think it would probably be better to propose a new standalone policy page. --Tryptofish (talk) 19:15, 30 August 2025 (UTC)[reply]
Editors can still lie about their LLM usage (the same way editors can lie about not being a paid editor or a sockpuppet), but it's better than nothing I guess. Some1 (talk) 23:12, 27 August 2025 (UTC)[reply]
As second choice, support. In case the proposal to ban all AI-generated comments and proposals does gather consensus, the disclosure of such comments would be alright. It still wouldn't be perfect because it would waste the time of editors. Still, something is better than nothing. 🇪🇭🇵🇸🇸🇩 Easternsahara 🇪🇭🇵🇸🇸🇩 16:09, 2 September 2025 (UTC)[reply]
I proposed this some time ago as WP:LLMP, which at its RfC had many more supports than opposes, so I would support it being passed as a separate thing. jp×g🗯️19:52, 13 September 2025 (UTC)[reply]
Just wanted to step back, because I think we are wandering off course. There are several different issues to deal with when it comes to using LLMs in Wikipedia that we seem to be conflating:
Using an LLM for research (behind the scenes).
Using an LLM to generate text and citations in ARTICLE Space.
Using an LLM to generate text and arguments in TALK Space.
I think we need separate approaches to each of these: #1 is allowable, but we should advise editors to use with caution. #2 is NOT allowable at all. #3 is discouraged, but should be allowed with disclosure. Blueboar (talk) 17:12, 30 August 2025 (UTC)[reply]
It's more complicated than a simple yes/no in all of these cases. As ever with LLM-related proposals nuance is missing. Using LLMs to generate text and then posting that text to Wikipedia without review is, by consensus, not allowed. However using LLMs to generate a framework around which you write your own words, using an LLM-based tool to check your text for e.g. spelling/grammar, using an LLM to assist with translation, using an LLM to suggest sources, and similar are all acceptable provided that the final review is human and (at least in talk spaces) the essential comments/arguments originate from a human. Thryduulf (talk) 18:00, 30 August 2025 (UTC)[reply]
I'm grasping for something, and would be thrilled if someone could come up with a solution for it. Is there a way to simply and clearly articulate what distinguishes the kind of harmless "behind the scenes" use of LLMs from the kinds of uses that are likely to be unhelpful? --Tryptofish (talk) 19:10, 30 August 2025 (UTC)[reply]
Much of the problem with the LLM-related discussion is treating something that is inescapably complicated and nuanced as a binary "good/bad". However if you absolutely must have a single sentence, then the best I can come up with is: Problems are most likely when LLM output has not been subject to active human attention and review as (at least) the final step in the chain. That's not to say that all human-reviewed LLM output is good or that all LLM output unreviewed by a human is bad (because neither is true) it's just a probability gradient. Thryduulf (talk) 19:26, 30 August 2025 (UTC)[reply]
Thanks for that, I think it's useful. Just to clarify, it isn't like I must have a single sentence. Rather, I'm trying to figure out how to develop a policy proposal that will work (and even reflect the wishes of skeptics like you), and I'm using the discussion here to crowdsource ideas for how to do that. --Tryptofish (talk) 19:32, 30 August 2025 (UTC)[reply]
Another thing to keep in mind is the future: Imagine that it's a few years from now. The technology has gotten much better. The results are usually indistinguishable for something like a talk-page comment. And, of very high importance, a whole generation of students has been explicitly taught to use these tools in school, so they think it's everyday normal behavior – no different from our generation using predictive typing to get spelling correct or to save a little time when typing an e-mail message.
In this world of integrated AI tools, Wikipedia has a simplistic Official™ Policy that says Thou Must Disclose the Use of Any Generative AI Tools in Thy Talk Page Comments.
Do you think that policy will be respected? I've got some doubts. I'm wondering if it might sound a lot like "Please disclose that you're using a computer, 'cause us old folks need reminders about the existence of all this newfangled technology".
If we adopt a policy to require disclosure in discussions, I wonder if we'll see WP:CUSTOMSIG used to make sure that every possible comment is disclosed. Instead of "(please ping)", it'll be "(uses LLMs)". Or maybe a user script to add a disclosure (e.g., "may have used an LLM") as an edit summary if the edit is over ~100 words.
Wikibooks discussed an AI policy a while ago. Their risks are higher than ours, but some of the proposals were massive overreach (e.g., if you use an LLM, you need to post the entire transcript of your discussion with the LLM on the talk page). I think this is much more reasonable, but I wonder if it has legs, or if we'll be repealing it a decade from now. WhatamIdoing (talk) 05:49, 31 August 2025 (UTC)[reply]
The tools have gotten better, and anecdotally it feels easier to find AI-generated edits from the earlier LLMs of 2023, even though you'd think it'd be the opposite as there's more time for people to revise the text.
That's part of why I am pushing for as full disclosure as possible -- what tool, what prompts, what process -- because if we can get a reasonable sample set of edits made with ChatGPT 4 vs. ChatGPT 5 vs. Gemini , etc., we might be able to determine some indicators of AI use that haven't been (apologies for the AI-esque language) widely publicized yet.
Not a fan of the 100-words cutoff though. In practice, this will be done via diff size, and a lot of AI edits revise text substantially but show small increase/decreases in page history. And even if the edit actually is small, it can still contain hallucinations -- for instance, inaccurate or non-neutral photo captions. Gnomingstuff (talk) 17:37, 1 September 2025 (UTC)[reply]
I believe that in the visual editor, you could get a count of how many words are 'touched' by an edit, and thus you could realistically have a zero-net-bytes edit flagged as changing a larger amount of text.
But mostly I think that if we require disclosure, we'll be seeing technical compliance – not "I used an LLM to write this specific talk page comment", but "Hey, I'm disclosing that I'm the kind of person who sometimes uses LLMs". WhatamIdoing (talk) 21:58, 6 September 2025 (UTC)[reply]
You can't just handwave away all the arguments that explain all the detail and nuance and then say there isn't any nuance. That's not how things work in the real world (which is the only world we, as mature and intelligent adults, should be dealing with). It's absolutely not a case of "LLM = bad". Thryduulf (talk) 19:46, 30 August 2025 (UTC)[reply]
If one wants to consult an LLM/AI, one can do that without the need to do so via Wiki/a Wiki editor. If we all want to include LLM/AI stuff into WP, then just stick a google type analysis or a prompt together with suitable caveats into the main text of articles that anyone can consult if they please. Selfstudier (talk) 16:45, 31 August 2025 (UTC)[reply]
@Thryduulf Just curious, what is your thoughts on the required disclosure (above)? I understand where Blueboar is coming from, but any step we can take towards transparency is a step worth taking, but curious how you feel about it. —Locke Cole • t • c20:48, 30 August 2025 (UTC)[reply]
In a word, complicated. I can't object to disclosure in principle, but I'm not certain what benefits it will bring in practice and worry that it will be misused. Specifically, I can easily see all of the following behaviours happening.
Edits that are disclosed to have had some LLM use just ignored/hatted/reverted/disregarded based on that alone without the content of the edit being even looked at to see whether it is actually good or bad
Editors being harassed because they didn't disclose LLM use in a edit that someone suspects (with or without good reason) was LLM-generated, even if the editor is telling the truth and they didn't use an LLM.
Editors being harassed because they didn't disclose LLM use for an edit, without regard to the content of that edit, based solely on a previous edit being disclosed as LLM-assisted. This will happen even when the editor is telling the truth.
False positives and false negatives due to editors not understanding what "LLM" (or some other term) means and/or not understanding what we mean by whatever term is used.
Different understandings of what constitutes LLM-usage (is it any use of an LLM? Only when the exact words in the edit were generated by an LLM and not reviewed? Somewhere in between?) leading to disagreements over whether an edit should or should not be marked as LLM-assisted. Such arguments will detract from the actual content of the edit (in some cases leading to the content being ignored completely).
Not every edit will result in one of these types of behaviour, but all of these that do will actively harm the encyclopaedia (not all in the same way), potentially very significantly, and all entirely unnecessarily. If we just accepted that just as some human edits are good and some human edits are bad, some LLM-edits are good and some LLM-edits are bad and that we can and should deal with them appropriately in each case without needing to know or care whether a good (bad) edit is a good (bad) human edit or good (bad) LLM edit or a good LLM-and-human edit. Thryduulf (talk) 22:51, 30 August 2025 (UTC)[reply]
Thanks for the feedback, I definitely feel like there's an opportunity to instruct and not simply penalize or restrict here. I still think the sheer volume of these types of edits are the primary cause for alarm. I don't think anyone here wants to harass other editors, but as with any "rule", there is always the potential for abuse or misunderstanding. —Locke Cole • t • c17:27, 31 August 2025 (UTC)[reply]
I don't think anyone in this discussion intends to harass other editors, but (per WAID) experience has already shown that regardless of intent, editors are being harassed. We should do our utmost to avoid that, and part of that is not instituting policies that stand a high likelihood of (unintentionally) enabling or encouraging harassment while simultaneously providing little to no benefit to the project. Thryduulf (talk) 22:42, 31 August 2025 (UTC)[reply]
I think this could actually be made in an even simpler way than an edit summary, by adding a checkbox next to the existing "minor edit" one. Wikimedia Commons already has a "this image was made by an artificial intelligence tool" checkbox, and, while the situations aren't directly comparable, most users are not fundamentally dishonest to the point of lying about this. Agree with your point regarding spell-checking errors, although these are, usually, easier to catch (grammar errors, or meaningless words similar in orthography to more relevant ones). Chaotic Enby (talk · contribs) 22:27, 27 August 2025 (UTC)[reply]
A checkbox would be great. But even just updating the system messages (the ones that display licensing information) to include a warning and link to the current LLM guidance would be an improvement. —Locke Cole • t • c22:32, 27 August 2025 (UTC)[reply]
CE said Wikimedia Commons already has a "this image was made by an artificial intelligence tool" checkbox, and Commons runs MediaWiki, so if they can do it, I can't imagine we couldn't do something similar. —Locke Cole • t • c01:07, 28 August 2025 (UTC)[reply]
Wikimedia Commons' Upload WizardHere is what it looks like, for reference. What I'm having in mind is a more lightweight checkbox that adds a tag to the edit (or, if it can't be done directly, switching a variable that the edit filter extension can then catch to add the tag). Disclosing the model and prompt might not be as useful, although they could technically be appended to the edit summary with a small dose of Javascript. Chaotic Enby (talk · contribs) 01:17, 28 August 2025 (UTC)[reply]
Hmm, yeah I think Special:Upload is a bit more customizable, though everything we see in the interface should be changeable somehow, see Special:Allmessages (which there's hundreds, maybe thousands, but there's some search functionality if you want to go digging). We could also ask at WP:VPT since there's plenty of folks who know this stuff under the hood more lurking there. —Locke Cole • t • c01:27, 28 August 2025 (UTC)[reply]
It looks like the dialogue box for "publish changes" has many components, including
Having a checkbox is a very good idea, that I hadn't thought of. Perhaps, that might negate the need to propose a policy. On the other hand, I can think of two potential friction points. One is that an editor who makes bad-quality edits, but consistently checks the checkbox, might complain that there's nothing wrong with their edits because they used the checkbox, so why were their edits reverted? The other is whether or not we need a policy for someone who keeps making bad-quality edits, and ignores the checkbox. --Tryptofish (talk) 21:31, 28 August 2025 (UTC)[reply]
The checkbox wouldn't negate other content policies, so an editor making bad quality edits but using the checkbox wouldn't have any kind of immunity. In my mind, it is similar to the situation at AfC with COI disclosures – editors can and often do make the disclosure in the Wikipedia:Article wizard , but that doesn't make their submissions immune to other kinds of feedback or criticism. Chaotic Enby (talk · contribs) 21:55, 28 August 2025 (UTC)[reply]
Yeah, I think that gets it right. The checkbox is a technical feature that can and should be pursued independently of the policy-related ideas we are discussing here. --Tryptofish (talk) 21:58, 28 August 2025 (UTC)[reply]
It needn't necessarily even be a checkbox. Don't get me wrong, that would be great (but I suspect then everyone would want a checkbox for things that are, ostensibly, equal to or greater than LLM/AI discloure (like COI, or copyright/plagiarism, or paid editing; the list is long). The other possibility is adding something to the boilerplate text (in replytool the By clicking "Reply", you agree ... language; the full interface editor has something similar). Something short, like You agree to abide by our LLM/AI disclosure rules, and that failure to do so may lead to blocks or bans. With wikilinks to appropriate pages should disclosure become policy. —Locke Cole • t • c22:34, 29 August 2025 (UTC)[reply]
Copyright/plagiarism is already banned, and copying with attribution needs the attribution in the edit summary (a simple yes/no check wouldn't work), but COI/paid editing could absolutely also deserve a checkbox. If anything, both that and AI disclosure are more important than the current "minor edit" checkbox, which is often misused and doesn't actually tell much. Chaotic Enby (talk · contribs) 20:38, 30 August 2025 (UTC)[reply]
Oh I know they're already restricted, I was just pointing out that if we start down this path, it wouldn't be much to think that we'd end up with 4-5 checkboxes before you know it. And then contributing to Wikipedia would turn into a CAPTCHA-esque triathlon of mouse clicks/screen taps just to submit something. However, a short sentence (with links for further details) about how we require LLM/AI disclosure (assuming Tryp's idea gains community support). As Tryp rightly points out below, however, there is the risk of "banner blindness" if we just add some text and people ignore it completely (the 'ol "officer, I didn't see the speed limit sign"-excuse). —Locke Cole • t • c21:16, 30 August 2025 (UTC)[reply]
New editors who see a checkbox that says says "this edit was created with the assistance of an LLM" or otherwise will likely view it as a tacit endorsement by the project of LLM editing. This is in misalignment to current community sentiment. I'd oppose the addition of any such checkbox. fifteen thousand two hundred twenty four (talk) 22:45, 28 August 2025 (UTC)[reply]
Perhaps, but I agree with 15224 that we should not use language that will mislead them into thinking that the community accepts this. --Tryptofish (talk) 22:56, 28 August 2025 (UTC)[reply]
I think it would ultimately encourage more editors to use LLMs and lead to more LLM-based edits made to the encyclopedia. This is an undesirable outcome. On top of this, editors already have enough problems properly utilizing the minor edits checkbox, and I expect self-snitching compliance with such a checkbox to be extremely low. The harm will well outweigh any theoretical good. fifteen thousand two hundred twenty four (talk) 23:12, 28 August 2025 (UTC)[reply]
"large proportion" – Compared to total AfC users? Sure. Compared to total undisclosed COI editors? I'd say that's unknowable. Based on my limited experience with some UPE farms I'd guess there's more not disclosing than disclosing. And asking for COI self-disclosure carries a lower inherent WP:BEANS risk than a checkbox for disclosing LLM use. fifteen thousand two hundred twenty four (talk) 23:52, 28 August 2025 (UTC)[reply]
It looks to me like nothing about the checkbox idea negates the possible proposal being discussed here, so I think that it's really a separate topic that, if people want to explore it further, should be taken to a talk section of its own. --Tryptofish (talk) 00:19, 29 August 2025 (UTC)[reply]
I think it would ultimately encourage more editors to use LLMs
Honestly, I doubt this. ChatGPT has been around for 2 years and has a great deal of name recognition and regular use. If someone's using an LLM to contribute to Wikipedia, they're probably routinely using AI already and were going to do it anyway. I can't see a situation where someone comes to Wikipedia not intending to use ChatGPT, then changing their mind when they see the checkbox, after they already made the edit.
As far as "self-snitching compliance," you would be surprised at how many people will be open about using AI if you ask politely. (If you ask adversarially, which is what people are doing more often, then they won't.) The risk isn't so much people lying as people not knowing how substantial AI edits can be. A pretty common scenario, for instance, is someone whose first language is not English asking ChatGPT to generate a Wikipedia editing prompt, and then feeding that AI prompt back into ChatGPT or some other AI tool. Even if English is your first language, AI editing tools advertise a lot of use cases and it's unclear what the differences are -- usually because it's marketing and the details are deliberately vague. Gnomingstuff (talk) 19:30, 30 August 2025 (UTC)[reply]
My concern is less about making editors aware that LLMs exist and could be used, and more about doing everything we can to not look like their use is endorsed in any form. As said above I think many will see it as tacit endorsement of model use, and take it as permission to go ahead in the future.
How would you feel then about a checkbox with something along the lines of "this edit was created with the assistance of an LLM, and I attest that I personally verified the accuracy of the generated text"? CoffeeCrumbs (talk) 19:17, 30 August 2025 (UTC)[reply]
We can't say "LLM," people aren't going to know what that is. We have to say "AI," and we probably should also include some examples, like "such as ChatGPT, Perplexity, etc.).
I don't think it matters what text accompanies it, if the text indicates LLM use is ok in some form so long as a box is checked, that's the association that will be made.
A secondary concern is the fact that LLMs have numerous shortcomings that are harmful to the encyclopedia, far too many to cover in a snippet, and a link to more information would go largely unread. fifteen thousand two hundred twenty four (talk) 20:06, 30 August 2025 (UTC
Yeah, those are good points. I'm less and less convinced that we can make a succinct enough checkbox that doesn't convey the "LLMs are a valid way to contribute" impression. Chaotic Enby (talk · contribs) 20:43, 30 August 2025 (UTC)[reply]
That's what I'm coming to think, too. As I've been following this discussion, I think the combination of "banner blindness"/didn't read, along with the misimpression that LLMs are a valid option, are things we won't be able to get around, no matter how we try to frame the checkbox question. --Tryptofish (talk) 20:49, 30 August 2025 (UTC)[reply]
However, there are concerns. I see some editors here showing their concern that using such a 'disclosure checkbox' might encourage Wikipedia users to use AI more than before.
I might as well request them to the see the other side of the coin. I've seen a lot of editors in this discussion having a knee-jerk reaction against the use of AI. So as soon as someone adds the 'AI tag' in their addition through the checkbox, these type of editors will instantly take 'em down regardless of the value they might add to Wikipedia.
As such, I think there should be a proper guideline to the editors, as on how to be benevolent to good faith AI additions which are clearly useful to Wikipedia, before adding such a checkbox.Cdr. Erwin Smith (talk) 05:47, 3 September 2025 (UTC)[reply]
The number of uploads on Commons that claim own work when they are definitely not limits my enthusiasm for submission checks. Regarding the concept, if the aim of the checkbox is to find edits to revert, then that sets it up to be detrimental to the more honest editors. CMD (talk) 09:32, 3 September 2025 (UTC)[reply]
That's a good point, although Commons also has AI disclosure, and most of the undisclosed AI images that I've found are from people who were spamming anyway. Gnomingstuff (talk) 13:52, 3 September 2025 (UTC)[reply]
CMD makes a very good point. People claim "own work" on Commons all the time. Cross-wiki/within-the-editor uploads have been restricted because people think "Well, if I don't claim that this corporate logo/album cover/normal thing to include is 'own work', then it won't let me upload it. So of course I tick the box!" An interface item that requires disclosure will, at least by a non-trivial group of users, be ticked or not based on what they believe will produce the results they want. WhatamIdoing (talk) 02:55, 4 September 2025 (UTC)[reply]
The RfC isn't about Wikimedia. It's about 'discussions seeking community input' in Wikipedia.
It's not off topic. Human behavior is the same everywhere, especially when it's the same humans. An editor who – right here, at the English Wikipedia, in the 2010 wikitext editor – will click the 'Image' button in the toolbar, click the "Upload" button in the dialog box, and then tell an outright lie when faced with a tickbox that says "This is my own work" is an editor who – right here, at the English Wikipedia, in the 2010 wikitext editor – will equally tell an outright lie when face with a tickbox that says "I certify that I wrote this myself without using AI".
There is no reason to believe that Wikipedia editors will frequently lie when shown one tickbox in the wikitext editor and yet be reliable truthful when shown a very similar tickbox in the same editor. WhatamIdoing (talk) 21:45, 4 September 2025 (UTC)[reply]
To explain myself, what I wanted to say is that there's no such stringent licensing requirements in most of the Wikipedia "discussions seeking community input", as opposed to Wikimedia where it's very stringent.
So I think people will be more willing to disclose the use of AI. But it should only be done with a proper guideline on how to handle such requests benevolently, and not for the sole purpose of striking them down. Cdr. Erwin Smith (talk) 13:07, 5 September 2025 (UTC)[reply]
Oppose - Many people use LLM to improve their own grammar, including me. You have to realize that we have Wikipedians from all over the world with English as not their first language and have poor grammar. Instead of completely disssallowing it, meybe there needs to be a disclosure by the person that used LLM and an explenation as to why they used it. I also don't beleive anyone requesing RFC, AFD, etc with use of LLM has any other intent than posting what they intent to post. At the end they are probably reading what the the AI said and maybe even revising it before posting it.Darkm777 (talk) 18:39, 6 September 2025 (UTC)[reply]
(Unfortunately, your !vote here demonstrates the reality in which we increasingly have to work. It's a reality where editors who ostensibly characterize LLMs as purely supplementary or secondary to their participation in discussions, are nonetheless using them in some manner where they take time to read and understand what other editors have actually said far less than would otherwise be necessary to participate, yet replying as if that matters little to others – whether one's efforts to communicate are equally justified if they get processed solely by a prompt on the other side without the ostensible person in the equation bothering whatsoever to chip in to the discussion.) Remsense 🌈 论18:51, 6 September 2025 (UTC)[reply]
Yes, or you can put it through a grammar checker like the one built into Microsoft Word, Grammarly or whatever. I'd rather read a comment with bad grammar and no puffery than something with the most exquisite grammar, so good that i start convulsing with joy, and even a little bit of puffery. 🇪🇭🇵🇸🇸🇩 Easternsahara 🇪🇭🇵🇸🇸🇩 23:33, 6 September 2025 (UTC)[reply]
I'm a bit skeptical about the checkbox. There is a grey area here - some editors use LLMs to write whole posts and some use them to check grammar or style. If marking one's edit as AI-assisted gets perceived as diminishing the strength of one's argument, editors will tend to "forget" to mark their edits.
Also, it took me a couple of minutes to get the GPTZero score of a purely AI-generated text to 54% and I'm sure I'd be able to reduce it even more with a bit more effort. So since we have no reliable way of detecting these edits we we'd create an incentive to lie without any means to counter it. Alaexis¿question?21:18, 8 September 2025 (UTC)[reply]
Since the discussion is slowing down, I'll be giving my final opinion on the whole debate.
Oppose the speedy closure of "discussions seeking community inputs" written by AI.
Support a Checkbox for AI disclosure, with the AI category having a 3rd subcategory asking people to state 'why' they used the AI, or their 'purpose' - Fixing Grammar/Finding Relevant Policies/Writing 'XYZ Edit or Request' Partially/Writing 'XYZ Edit or Request' Fully.
Support a specific policy for all editors to act neutral and treat such AI Edits/Requests equally as they would a Human Edit/Request (Note : A proposal on not flooding the AfD either by AI/Human is being worked upon).
I have many issues with your last point, but probably the most important is that Wikipedia does not have "higher-tier editors" or different policies for them. jlwoodwa (talk) 00:28, 12 September 2025 (UTC)[reply]
Policies apply the same for everyone, sure. But there's definitely a hierarchy present in Wikipedia based on tools and user rights, and one can only climb the ladder step by step on the basis of their actions. The number of users decreasing drastically in each higher level is a proof.
However, you are partially right. Although the influence of the higher-tiers is much bigger, I did forget that Autoconfirmed users can also participate in many of the 'discussions seeking community inputs'. So the same ruleset should apply to them as well. I would also be adding the ongoing AfD issue which is being worked upon. Cdr. Erwin Smith (talk) 10:34, 12 September 2025 (UTC)[reply]
Consensus among a limited group of editors, at one place and time, cannot override community consensus on a wider scale. For instance, unless they can convince the broader community that such action is right, participants in a WikiProject cannot decide that some generally accepted policy or guideline does not apply to articles within its scope.
I don't think it's unreasonable to conclude that while some parts of MOS are the result of consensus with significant participation, there may be other parts that are indeed consensus among a limited group of editors, at one place and time.
Also of note are the proposals by L235 that did not make principles for that case. Specifically,
Policies and guidelines have a combination of prescriptive and descriptive characteristics. Policies and guidelines document community consensus as to "standards [that] all users should normally follow" (Wikipedia:Policies and guidelines), giving them some degree of prescriptive force. Simultaneously, policies and guidelines seek to describe "behaviors practiced by most editors" (Wikipedia:Policies and guidelines), and change with community practice, giving them a descriptive quality. Naturally, disagreements regarding the extent of a policy's consensus or prescriptive effect arise from this combination, and the text of a policy can sometimes diverge from or lag behind community consensus. These disagreements, like all disputes on Wikipedia, should be resolved by discussion and consensus.
Does MOS necessarily indicate community consensus on a wider scale? In other words, should closers examine the specific text for level of consensus before using it to overrule a (potentially larger) group of editors? Good day—RetroCosmostalk01:45, 26 August 2025 (UTC)[reply]
I would agree with L235, and add that, ideally, policies and guidelines describe community consensus and prescribe editors to follow this consensus. Regarding the MoS, as a set of guidelines with various ranges, it is expected that not all of its pages will have the same level of consensus – a very specific topic will attract less interested editors, and thus naturally have a lower CONLEVEL. That in itself is not necessarily problematic. However, if it goes against a wider consensus, or only reflects a subset of the views of editors interested in that topic, then there is indeed a CONLEVEL issue and a broader discussion should be held. Chaotic Enby (talk · contribs) 15:31, 26 August 2025 (UTC)[reply]
As a closer, I would not feel justified in going on an independent fact-finding mission to determine the level of consensus that supports a specific policy or guideline. I would support overturning closures that were based on such an independent mission. If participants in the discussion gave valid arguments based on their own analysis of the level of consensus, I would consider that when making my decision.To put it another way, I presume that guidelines and policies have a higher level of consensus than any local discussion. A mass of editors who disagree with a guideline should be directed toward venues where guideline change can happen, not a local discussion. Firefangledfeathers (talk / contribs) 15:53, 26 August 2025 (UTC)[reply]
Consensus isn't only found by discussion, but also by use. Maybe four editors discussed a particular piece of policy or guidance, but many editors may follow it because they also support what has been said. If editors disagree with any particular price of guidance then they should start a centralised discussion in whatever forum would be appropriate. So the answer to the specific question is probably, maybe, but to start discussion on specifics as required. Certainly the MOS in it's entirety has some level of wide scale support, even if it's quite possible that not all of it does. -- LCU ActivelyDisinterested«@» °∆t°12:42, 27 August 2025 (UTC)[reply]
ActivelyDisinterested is absolutely right. Many long-standing aspects of the MOS have strong consensus not because of the number of editors involved in the original drafting, perhaps decades ago, but because they have been widely followed without significant challenge ever since. It would be quite unworkable for closers to start undertaking historical investigations about the origin of about any particular rule in order to determine how seriously it is to be taken. All MOS rules should generally be followed per WP:MOS, and if a later group of editors think the rule is wrong they always have the option to open a centralised discussion suggesting that it be changed. MichaelMaggs (talk) 13:23, 27 August 2025 (UTC)[reply]
To answer the question Does MOS necessarily indicate community consensus on a wider scale?, I would say the answer is a clear yes. Closers should not try to deep dive the history of how certain parts of the MOS came to be in determining a local consensus on (for example) an article talk page. Instead, those concerned with MOS should go to the MOS talk page and open a discussion there to enact change. And I would say this for any policy/guideline (including notability guidelines, for example, where I've found discussions were limited to 2-3 people for some changes, but those changes have stood for over a decade). —Locke Cole • t • c19:45, 27 August 2025 (UTC)[reply]
I think this RFC question would have benefited from some additional workshopping. There are two unrelated questions being asked:
Is the MOS prescriptive, descriptive, or both?
Does the MOS have consensus?
My answer to the first requires you to know what prescriptive and descriptive mean. The MOS is both, depending upon the level you analyze it at. It is descriptive in the sense that the community wants to follow the rules of good grammar, punctuation, and other elements of writing style that are relevant to an encyclopedia. We follow these; therefore, a style guideline saying to follow these accurately describes the community's practice. At a more specific level, the MOS is prescriptive: instead of saying 'the community uses good punctuation practices' (descriptive), it says 'the correct punctuation practice to use is this one' (prescriptive).
My answer to the second is that you should assume, unless and until you can prove otherwise, that any page with a {{guideline}} tag at the top is exactly that community consensus on a wider scale that is mentioned in CONLEVEL. RetroCosmos, since this was all before your time, let me tell you in very concrete terms what CONLEVEL is actually about: CONLEVEL means that when MOS:INFOBOXUSE says The use of infoboxes is neither required nor prohibited for any article, then a handful of editors at Wikipedia:WikiProject Composers are not allowed to say "Yeah, well, that might be what the official Wikipedia guideline says, but they're prohibited for our articles, because we had a private chat among just our little group of editors, and we decided that the official Wikipedia guidelines don't apply to us". Trying to apply the MOS (or any other policy or guideline) = not a CONLEVEL problem. Declaring "your" articles exempt from the MOS = possibly a CONLEVEL problem. WhatamIdoing (talk) 20:30, 27 August 2025 (UTC)[reply]
This RfC is overly broad. Most of the MOS is supported by strong affirmative consensus. I encourage editors who take issue with a particular part of the MOS to start an RfC asking whether that particular part currently has the support of the community. Such narrow discussions would be far more productive than philosophizing on the nature of the MOS as a whole. Toadspike[Talk]06:07, 30 August 2025 (UTC)[reply]
This RfC is not helpful because standard procedure acknowledges that no set of rules can apply in every circumstance. The Article_titles_and_capitalisation_2 Arbcom case concerned extreme disruption over an extended period. That can occur with any policy or guideline. A favorite that pops up from time to time is WP:V where people go around deleting chunks of correct and well-written material because no one has added citations. WP:V definitely applies everywhere but dumbly pushing it wll result in blocks. Johnuniq (talk) 06:42, 30 August 2025 (UTC)[reply]
Even if we accept, for the sake of argument, that the topic-interested in an MOS discussion might sometimes result in an MOS issue resulting in a local consensus, the solution certainly wouldn't be to defer to a local consensus, which is far more likely to represent a local consensus. If there are concerns that an MOS consensus was not agreed upon by a sufficiently wide cross-section of editors, then the solution would be to discuss that consensus in a place likely to be seen by a wide cross-section of editors.CoffeeCrumbs (talk) 19:07, 30 August 2025 (UTC)[reply]
Right. All guidelines, including all MOS pages, are presumed to have full community (i.e., non-local) consensus. However, there are hundreds of guidelines with thousands of pieces of advice, and at any given point in time, some small fraction will be out of date, badly explained, not reflective of current community practices, etc. Whenever those problems are identified, editors should fix them. That can be done through bold editing, through ordinary discussions on the guideline's talk page, through RFCs, etc. And even if the advice is sound in general, there might be reasons to not apply it in a specific instance. But you should not start from a position of assuming the MOS to be a WP:LOCALCON. It might be wrong, and it might need to be changed, but it's not a local consensus. WhatamIdoing (talk) 05:59, 31 August 2025 (UTC)[reply]
I don't know what the status is now, but I remember when the MOS had large parts written by a small group who hung out on the MOS talk pages, fiercely arguing with anyone who came there with an opposing viewpoint to preserve their desired version. Anomie⚔11:35, 31 August 2025 (UTC)[reply]
As a participant in the arbitration case referenced in the opening, I feel I should point out that the issue there wasn't disagreement with the MOS but disagreement over how a particular section (MOS:CAPS) is interpreted. ~~ Jessintime (talk) 11:53, 31 August 2025 (UTC)[reply]
That was a reckless charge during the arb case. If something, in fact, lacked WP:CONLEVEL, then it should have been changed by a larger consensus. The case failed on that point. —Bagumba (talk) 14:08, 31 August 2025 (UTC)[reply]
The answer to the question "Does MOS necessarily indicate community consensus on a wider scale?" is generally no. The MOS is by and large the result of WP:BOLD editing and even when there is a discussion it usually involves only a very small number of people. It therefore reflects local consensus. Much was written before guidelines became elevated to the status they hold today and at best has implied consensus owing to having been there for years without being changed. In cases where it has proven too burdensome, it has indeed been overridden by a larger consensus. Most editors cannot be bothered. Some parts have never been able to reach a consensus. Mainly, though, we have an ongoing iterative process of improvement. Hawkeye7(discuss)03:45, 3 September 2025 (UTC)[reply]
I reject the notion that two editors on an MOS talk page represents community consensus better than fifty editors on Wikipedia:WikiProject Composers. Consensus among a limited group of editors, at one place and time, cannot override community consensus on a wider scale. That applies to the MOS talk pages every bit as much as project talk pages. Like most editors, I am happy to follow local consensus. Hawkeye7(discuss)23:01, 3 September 2025 (UTC)[reply]
I agree with Hawkeye, what matters is the visibility and scale (number of participants) of a discussion, not the venue. Obviously the venue is not irrelevant - a discussion at VPP is more likely to be accidentally discovered than one at e.g. Wikipedia talk:WikiProject Poetry, but if the latter is well-advertised and attracts 30 editors the consensus it establishes is more likely to reflect community consensus than an un-advertised discussion at Wikipedia talk:Manual of Style/Titles of works with only three participants. This is especially true if the subject of the discussion is specific to poetry and the consensus is to adopt the style that's been consistently used by a significant majority of relevant articles for many years. Obviously there are exceptions to this (e.g. if the de facto standard is inaccessible) but those exceptions need to be supported by evidence of an actual problem and an alternative must not be blindly and rigidly enforced without discussion to see if a compromise can be reached. See Wikipedia talk:WikiProject UK Railways/Archive 48#DLR colours for a semi-relevant example. Thryduulf (talk) 00:23, 4 September 2025 (UTC)[reply]
But do you also reject the notion that two editors on the guideline's page is better than two editors on any other page, when the purpose of the discussion is to improve the guideline?
Or imagine that it's not a guideline. If you and I have a chat on an article's talk page, is that better than you and I having the same chat on your talk page? WhatamIdoing (talk) 02:58, 4 September 2025 (UTC)[reply]
do you also reject the notion that two editors on the guideline's page is better than two editors on any other page all other things being equal, the discussion on the guideline's talk page is slightly better, but its still a weak consensus. A discussion elsewhere that is advertised to multiple places, including the guideline's talk page, is stronger than one with approximately the same number of participants that was held on the guideline's talk page but was not advertised elsewhere. Also, where the elsewhere is can matter - a WikiProject talkpage is probably going to produce a stronger consensus than an article talk page, which in turn is probably' stronger than a discussion on your or my talk page.
Venue, number of participants, amount of advertising, significance of change (from both the de jure and de facto status quo), reason for the change, depth of discussion and degree of unanimity are all relevant considerations and you absolutely cannot look at one factor in isolation and arrive at a reliable answer. Thryduulf (talk) 10:30, 4 September 2025 (UTC)[reply]
A WikiProject's talk page is more likely to produce the appearance of unanimity. The people in that group are largely there because they like working with each other, after all, and we expect them to mostly agree with their chosen wiki-friends. It is also, for most subjects, likely to represent the views of editors who know something about the subject matter (e.g., if you have a question about a medical article, drop by Wikipedia talk:WikiProject Medicine, not a village pump).
It is, however, less likely to represent the broader community's POV, especially if the question is:
not a question in which the group's subject-matter expertise is relevant (e.g., WikiProject Composers on infoboxes; WikiProject Infoboxes on composers' genres) or
an interdisciplinary question (e.g., in which WikiProject Medicine and WikiProject History might have different perspectives on what's important to include in the article).
I don't know if this is a good example, but I uploaded an image which (to my understanding) was allowed by policy/guideline. The image replaced an existing fair-use JPEG with a fair-use SVG of a videogame box cover. Upon getting the deletion notification for the old JPEG, the editor that uploaded the JPEG passed on talking to me directly, or opening a discussion at the article talk page, or just taking it through WP:FFD. Instead they opened a discussion at a WikiProject and "unanimously" decided to remove the image there.
In my view, the WikiProject definitely has knowledge about videogames, but the issues being raised by editors there are more technical and/or concern NFC questions, so surely the discussion would have made more sense at the article talk page with pointers at WP:VPT, WT:NFC and WT:VG to this centralized discussion. —Locke Cole • t • c02:36, 7 September 2025 (UTC)[reply]
I think FFD might have made more sense, but I think the important thing to do right now is for you to post messages to relevant pages (e.g., WT:NFC) to bring in people who know less about what the group usually does, and more about what the Wikipedia:Non-free content criteria policy actually requires. WhatamIdoing (talk) 17:02, 7 September 2025 (UTC)[reply]
So, as I see it, there are a couple of things going on here which could influence how much "binding" consensus we should ascribe to any particular section/verbiage within the MoS. And these absolutely should be given serious consideration when applying any particular rule of thumb found within the manual, but in practice, these considerations are rarely cited, let alone heavily considered in debates that center around particular application in given use cases in article space. It would be nice if we had a more formalistic system for establishing the weight and uniformity to be ascribed to any given style principle, but the ad-hoc nature of the evolution of the MoS, combined with the fact that it was at one time meant to be purely advisory, but over time has taken on a less permissive tone overall, and with particular sections being almost entirely mandatory, that it would be very difficult to reverse engineer the entire body of style recommendations and re-code them in conformity with new and more express scheme for different levels of absoluteness with regard to different provisions. Though goodness knows that would probably save the community a lot of time on disputes if such a clearer system were implemented, so maybe it will be worth the effort at some point.That lengthy preamble made, here are the primary two factors that I think influence how much weight and certainty a given piece of style guidance should have:
First, was the discussion which lead to that verbiage the result of a full and appropriately approached WP:PROPOSAL? How many individual discussions were held, and how many community members took part in those discussions? Were the held in the right venue for the proposal in question (the talk page of the MoS subsection itself or the village pump, typically) and were they well advertised in other fora if the resulting rule was likely to effect a non-trivial number of articles? For example, on a significant number of occasions, small cadres of editors operating out of WikiProjects have tried to create rules (some of which were added to MoS pages without further authorizing discussion among the larger community. This of course is expressly forbidden by WP:Advice pages and a number of ArbCom rulings. On the other end of the spectrum, we have something like MoS:GENDERID, which is the result of a lot of community negotiation in some of the most massively-attended and assiduously-argued discussions in the history of the project. Some of argued that the resulting rules should have been codified in WP:PAG as a result, but for good or ill, it was placed in the MoS. But while there is some wiggle-room for most provisions in the MoS, there is a fairly absolute consensus at this point that no part of GENDERID is optional--though we continue to have arguments about how to apply it in particular cases. However, most provisions of MoS exist in a grey area between these two extremes. And unfortunately, because there are no handy labels to easily distinguish which are the result of more trivial or robust previous consensus discussion, it is often incumbent upon those arguing over a particular piece of guidance and its application to a given article or set of uses to either accept that they have to make pragmatic arguments for that use case, or else demonstrate that the history of debate for that provision shows previous and broad consensus for a universal approach, or that the particular use case in question has already been addressed. Again, suboptimal, but the reality we are left with after the organic and non-formalized growth of this part of our rules ecosystem.
Second, we can also look to the intrinsic text that was generated by the consensus process described above. Because traditionally (and less so as time went on, but still to some extent) we intentionally left a lot of flex in MoS wording itself, to account for previous disagreement and to allow editors to use their best sense of what was required for the needs of the individual article or other namespace. Rules creep has gobbled up the edges of much of that flexibility, but many sections of the MoS still have vague or expressly permissive language for those purposes. Personally, I think we benefit from keeping those provisions lean for those very pragmatic reasons, but it is a natural consequence of a bureaucratic apparatus such as we work with here that more and more rules will accrue over time. Especially as it has turned out that there is no principle of grammar, formatting, or presentation to trivial or inane that the Wikipedia community at large has proven unable to generate at least two camps of deeply committed proponents willing to regularly and disruptively go to war across hundreds or even thousands of articles/talk pages to enforce their preferred version.
All of which is to say, the MoS is clearly very prescriptive with respect to many considerations, but the degree to which a given prescription (or proscription) is permissive or mandatory is highly variable, and often nothing short of research into and reference back to substantially aged discussions can settle just how strong a given requirement is. And even then, everything is of course subject to WP:CCC. Only the most well known and at one time divisive subjects, like GENDERID, are so absolute that everyone is expected to comport with them in the vast majority of use cases, with failure to do so often being considered highly disruptive. But as time goes on, we have more and more of this body of uniform rules. A better system would re-categorize all style guidance into levels of permissibility in a system which roughly shadows the levels of weight seen as between information pages, guidelines, and policies, but such a re-conceptualization would be a herculean effort that I just doubt we even have the manpower for, even if we could get the broad community buy-in to support such a massive restructuring. SnowRise let's rap21:56, 3 September 2025 (UTC)[reply]
One thing I think gets lost here is that the process (where was the discussion? Was there a discussion? How many editors? How many experienced editors who haven't been blocked in the intervening years?) is not really as important as whether the policy/guideline/help/whatever page matches what the community wants now. A perfect process, with dozens or hundreds of people, that arrived at the (now) wrong conclusion is not nearly as important as whether the community agrees with that decision today. WhatamIdoing (talk) 03:02, 4 September 2025 (UTC)[reply]
I don't disagree in principle, but even if there is a new established best practice or general unspoken consensus, it's infeasible to allow editors to just assert it as a given; there needs to be a new formal consensus discussion at some level, as otherwise we will just have people insisting upon their own idiosyncratic views about what the "obvious" or "accepted" rule is--assumptions which are subject to every cognitive bias under the sun. In any event, you are touching upon another factor I had meant to list with the other two above: independent of the degree of formal consensus behind a given rule, or the certitude/universality of the wording of the rule itself, one can also point to the uniformity with which it has been applied. More than once I have seen wording in an MoS section, or even a guideline that it turns out was added despite no WP:PROPOSAL (or any substantial WP:CONSENSUS) process, but by the time this is caught years later, the community is willing to give it a free pass and basically endorse it despite these usual required checks. Either because it turned out to be the right utilitarian approach, or disentangling it from established best practice is more trouble than it's worth. All that said, I think the "accepted custom" prong of legitimacy ought to be treated as absolutely the least compelling and reliable factor. Not wholly irrelevant, but definitely to be taken with a grain of salt as arguing for the presumption that a given rule is practical or represents community support, express or tacit. SnowRise let's rap04:48, 4 September 2025 (UTC)[reply]
It's not feasible to have "a new formal consensus discussion" every time a policy or guideline is reworded.
Most policies and guidelines had no WP:PROPOSAL. I wrote PROPOSAL in 2008. Before then, exactly two (2) of the guidelines and zero of the policies had followed that process (WP:MEDRS and WP:MEDMOS). The original process was "slap a tag on it, and see if someone reverts you". After a while, the process usually became "have a small chat on the talk page, then slap a tag on it, and if someone reverts you, point them at the discussion on the talk page when you revert them back". And quite a lot of WP:Naming conventions, and some of the WP:MOS pages, achieved guideline status through the WP:MOVE button. But at this point, 17 years after the PROPOSAL process was adopted (its adoption being the third time that process was fully followed), and after the massive MOS cleanup project coordinated through Wikipedia:WikiProject Manual of Style (which delisted and rewrote a number of pages), I think we can safely say that anything that is still tagged as a policy or guideline is actually accepted as a policy or guideline. WhatamIdoing (talk) 21:54, 4 September 2025 (UTC)[reply]
I think there's some conflation of concepts going on here. With regard to "a new formal consensus discussion", I personally do not see that as typically involving a full formal WP:PROPOSAL process, or anything remotely like it, as a per se matter. At least for inline changes to existing PAGs or MOS pages, in the vast, vast majority of cases, much less is called for. PROPOSAL is for creating new guidelines wholecloth, not for iterative additions or amendments to existing policies. Nevertheless, I consider it a bit of a tautology that no change to a PAG (nor any other express community guidance codified in MoS or an info page) which has proven contentious can be argued to have a clear "community consensus" unless a consensus discussion actually took place, at some level and in some way endorsing a particular proposition. I appreciate that things were quite a bit more free-wheeling once upon a time, and respect your role in codifying some of our early standards on formalizing consensus at the PAG level (I did not know you were the original author of PROPOSAL, which is quite the contribution to the project's mechanics), but as you yourself alluded, we've come quite a long way since those seeds were planted, and today we have a much higher burden for formally adopting a rule. As such, the mere act of being able to point to a rule that just happens to not have been disturbed is never going to be the strongest form of evidence that the community has endorsed that principle (or would, if directly asked). Although I will grant you, the farther back the rule stretches without a formal challenge, or the more central the position of the rule in our most heavily relied-upon policies or processes, the more confident we can be in regarding it as a kind of consensus principle. That said, as to ". . . I think we can safely say that anything that is still tagged as a policy or guideline is actually accepted as a policy or guideline., I'm not sure I'd agree that is likely to be universally true, but let's put that to the side for present purposes. That's still a very different thing from saying "Every bit of verbiage placed within a guideline since it was adopted came about as the result of community consensus." And that's an important distinction when we are talking about the MoS in particular, since MoS changes tend to be for the purpose of ammending or adding to existing sections, rather than creating new ones. SnowRise let's rap00:16, 5 September 2025 (UTC)[reply]
My immediate coarse intuition is, of course, if an editor sees a substantive, questionable change to P&G without explicit consensus, they would be encouraged to yank that material from production at any time?
(If the initial RfC needs my own variation on this theme: I hope other editors are actively motivated to remove any material that can't be assumed to possess a clear prescriptive mandate – i.e. material possibly not reflective of consensus, explicit or otherwise.) Remsense 🌈 论23:59, 5 September 2025 (UTC)[reply]
You should only revert changes that you personally disagree with. It's not exactly that we "encourage" people to revert changes, but if you personally believe that a change is harmful or even probably harmful, then yes, you should probably revert it. If you're only a bit uncertain, it's probably better to take it to the talk page. WhatamIdoing (talk) 02:22, 6 September 2025 (UTC)[reply]
That's what I meant to say—in my mind, one could only discern a change could be against consensus if one directly disagrees with it first. Remsense 🌈 论02:24, 6 September 2025 (UTC)[reply]
I have been reducing my reverts for any editor with a track record of contributions and opting for Talk-first. For many editors reverting is very aggressive and Talk-first often leads to a better outcome. I try to explain reverts for editors who registered, usually "Sorry,...". IP editors with no edit summaries I just revert full stop. Johnjbarton (talk) 02:28, 6 September 2025 (UTC)[reply]
Often the very best move—though, in terms of policy, I would very much prefer and prioritize my disputed additions not being live parts of the document, and I think most experienced editors woudl agree with that too at least in theory. Remsense 🌈 论03:05, 6 September 2025 (UTC)[reply]
Precisely. We're talking about two distinct subjects here. On the one hand, the more abstract question of whether an addition to a PAG or style section has community consensus, whether it is subject to being summarily reverted, and how much the benefit or problem caused by that change either militates for its retention or reversion. And then on the other hand, the more idiosyncratic question of how a given editor feels about how to address a problematic change that arguably could or should be reverted. When you layer the two over one another, you get a broad range of responses from different community members, but they are in principle discrete questions; the "What is this change, and can/should it be reverted?" and "Now that I've made that decision in principle, how do I really want to go about it to maximize the chance of the optimal outcome, not just with respect to the a priori issue, but also while being constructive and collaborative, and also while keeping other project priorities in mind. Now, if we wrap back around to your initial question, and contemplate how much we want policy to encourage reversion in those circumstances, I would say we should at least be making the process relatively painless for them, if the change has proven at all contentious and there was no clear consensus. While WP:BRD is mostly conceptualized in the context of namespace contributions, I would say its even more essential when it comes to the language in guidelines: what is codified and memorialized in those pages should be more conservatively approached and should usually only happen with some degree of consensus discussion. Contributors should be discouraged from being WP:BOLD with PAGS or even the MoS. And if they aren't, we certainly want the standard to be that there is very little noise or drama from and objecting party exercising the R&D part of BRD. But I certainly don't fault anyone who would rather exercise a softer touch. Nobody should feel compelled to actively object if it wouldn't normally be their wont in that situation. SnowRise let's rap07:57, 6 September 2025 (UTC)[reply]
In short, being prescriptive in principle, the state of a P&G page over time (clearly) has greater stakes than that of any one article, and it seems healthy for whatever quasi-WP:OWN feelings editors may have while working on an article (i suppose, in the sense of "let me cook, watchlist voyeurs") should by contrast be wholly absent when in P&G-space. That sounds super obvious, but whatever. Remsense 🌈 论08:10, 6 September 2025 (UTC)[reply]
I agree with what SnowRise says above that it's important to distinguish between "Is this MOS page really a guideline?" (to which the answer is 'yes') and "Does this specific paragraph in this specific MOS page still have community consensus?" (to which the answer is variable, because there are a few bits that probably don't).
But @Remsense, it is possible to treat the policies and guidelines as too much like holy writ. If editors think they can improve them, whether that means making them clearer, less verbose, more reflective of daily practices, more in line with our values and principles, etc., then editors actually should try to do that, and be encouraged to do that. Bold editing of policies and guidelines is officially permitted by policy, and the fact is that a change made today and reverted tomorrow probably has no, or very little, effect on what editors actually do. (Though if you wait long enough, it can become a problem; I now wish I had reverted this dubious addition in 2012.) WhatamIdoing (talk) 22:30, 6 September 2025 (UTC)[reply]
We often have consensus on the wording of policies and guidelines, and we often don't have consensus on applications (one of which applications being, ignore). That's just the nature of the work, and then we have to work it out, in the moment. -- Alanscottwalker (talk) 21:24, 7 September 2025 (UTC)[reply]
I would say that for the most part the MOS should be followed unless there's a compelling reason otherwise; but it can be ignored when a stronger policy-based reason exists. Guidelines in general are not absolute (though they vary in how forcefully they're worded), but in particular even the most forcefully-worded parts of the MOS always lose to WP:NPOV / WP:RS / WP:V when those things come into conflict with it, because those things are core policy and the MOS just governs our, well, style; we're not going to sacrifice NPOV for mere stylistic issues. If there is a consensus on a particular article that we must do something that the MOS forbids in order to preserve NPOV or reflect the sources, then the core policies obviously win - there are very few "you absolutely must do XYZ without exception" from-above policies in Wikipedia, and none of them are part of the MOS. That said, I do think that overriding the MOS on anything of significance would normally be expected to require an argument like that, ie. you need some actual policy-based reason to do so - guidelines are followed unless someone can articulate a policy-based reason otherwise. But once someone has articulated a reasonable policy-based reason why they think other policies are in conflict with the MOS, it's a matter for consensus and discussion on that article, and generally speaking I would expect policies to win out. (Of course, people might disagree over whether there's an actual conflict, but that is something that local consensuses can cover, since it involves how we interpret and apply policies and guidelines in specific cases.) In situations where someone disagrees with following the MOS in a particular article but can't come up with a policy-based reason why (ie. it's basically just disagreement with that part of the MOS), they should probably challenge it directly - the point of the MOS is to give us a consistent style, so you need a better reason to override it than "I just like how this looks better." --Aquillion (talk) 15:58, 18 September 2025 (UTC)[reply]
What is Wikipedia’s official stance on Ai-generated content
What is wikpedia’s stance on showing Ai generated content outside of Examples of Ai generation? Like showing images, text, etc. Also, if oppose, why? And if support, Why? Datawikiperson (talk) 17:02, 2 September 2025 (UTC)[reply]
We are wrestling with it as we speak (there numerous currently open threads on several policy pages and noticeboards). However, the general consensus seems to be opposed. Blueboar (talk) 17:08, 2 September 2025 (UTC)[reply]
AI-generated images are already against policy, except when the image itself is notable, examples of AI generation as you mentioned, and other such edge cases.
AI-generated text is not currently against policy although we desperately need to get our shit together on it, because we have kicked the can down the road about for two and a half year and are now paying the price. It's also something where the general community opinion is at odds with that of the Wikimedia Foundation. Gnomingstuff (talk) 17:36, 2 September 2025 (UTC)[reply]
At its most basic there are two significant viewpoints among editors with regards AI-generated content (by which we almost always mean large-language models (LLMs) that generate textual output and generative Ai models that output images): the first considers all AI-generated content as bad, either because it is AI-generated (the objection is essentially philosophical) or because they believe that AI is incapable of producing content of a sufficient standard. The second viewpoint prefers that all content is evaluated on its own merits with AI-generated bad content treated and dealt with the same way as human-generated bad content, and AI-generated good content treated and dealt with the same way as human-generated good content.
Beyond agreeing that at least some AI-generated content is bad and that adding AI-generated content without any human input is undesirable, there is little common ground between the camps and neither can be said to obviously represent the consensus of the community as a whole. Obviously once you get into any sort of detail it becomes more complicated than this (e.g. even among those that regard all AI-generated content as bad there is disagreement about whether such content that has been reviewed by a human between generation and submission to Wikipedia should be acceptable), indeed one of my bugbears in discussions is a lack of nuance from some (sometimes many) contributors.
It's worth noting though that I am one of the most vocal proponents of the second viewpoint I describe above, while Gnomingstuff's views are closer to the first viewpoint (I don't recall ottomh where they stand with regard human-reviewed AI-generated content). Thryduulf (talk) 00:54, 3 September 2025 (UTC)[reply]
No, the concern about AI is that it will swamp discussions and overwhelm content checking. The view that an infinite number of gnomes will eventually investigate and fix all AI claims and references is naive. There may be no need to take strong action now, and perhaps there never will be. However, if the concerns of the anti-AI crowd are confirmed, it will become necessary to either surrender Wikipedia to those posting walls of text, or to delete waffle without proving to everyone's satisfaction that the waffle is disruptive. Johnuniq (talk) 02:19, 3 September 2025 (UTC)[reply]
This is not the place to remake the same fearmongering arguments you've made in every other place. They haven't convinced anybody who doesn't already agree with you there, and they aren't going to do so here. This is simply about outlining what the very basic positions are. Thryduulf (talk) 03:29, 3 September 2025 (UTC)[reply]
This is the critical point. One can argue all day that theoretically speaking there is no difference between an LLM and a hypothetical user who happens to make up plausible-looking paragraphs cited to sources that don't support them. But the fact is that in reality the LLMs generate orders of magnitude more of these paragraphs than humans do, by volume. Wikipedia functions only as long as volunteer editors can handle the work of fact-checking. Strict policies against LLM use are necessary for editors to handle the flood of misinformation as efficiently as possible. Elestrophe (talk) 08:56, 8 September 2025 (UTC)[reply]
Yup. One ant in my kitchen and ten million ants in my kitchen are two very different problems with very different solutions even if each individual ant is the same as the solo ant. If you see ten million ants in your kitchen, you definitely won't say "well, an ant can be in the house for no particularly concerning reason." CoffeeCrumbs (talk) 06:30, 12 September 2025 (UTC)[reply]
My personal stance is the second in theory but the first in reality: I don't have a philosophical problem with AI-generated text, but the actual stuff that exists right now is mostly crap.
But my real stance is that I don't care which viewpoint the community settles on as long as we just pick one already, and fast. Really, we needed to pick one 2 years ago, and so now we are not only dealing with 2 years' worth of accumulated, largely undetected AI slop, but sending new editors mixed messages when people go aggro at them over what is currently an essay. Gnomingstuff (talk) 04:25, 3 September 2025 (UTC)[reply]
I agree that we need to stop reacting aggressively against newbies. Perhaps a general announcement that, by way of establishing priorities, nobody should be screaming louder about AI slop than they do about poop vandalism?
But: Is it better to make the Wrong™ decision today, or the right one next year? Changing a policy or guideline is difficult these days. Once it becomes holy writ that Thou Shalt Not anything, it takes an enormous amount of effort to get that removed. WhatamIdoing (talk) 03:05, 4 September 2025 (UTC)[reply]
Honestly -- as someone who has complained loudly about undetected vandalism for years -- I think AI slop is now a larger priority than poop vandalism. There's no ClueBot for slop, it's more akin to subtle vandalism.
In many (possibly most, but I don't think all) of the currently ongoing AI-related discussions, doing nothing is the right answer because what is proposed is just a duplication of some existing policy and/or guideline. For example, we can already revert/hat/ignore nonsensical wall-of-text proposals regardless of whether they are AI-generated or not, we don't need anything additional. Thryduulf (talk) 00:36, 5 September 2025 (UTC)[reply]
We don't need new policies for articlespace either:
If the edit is good without needing to be edited, it's improving the encyclopaedia and we'd be shooting ourselves in the foot to get rid of it. This is how wikis work.
If the edit is good but needs polishing, then polish it or tag it for someone else to polish. This is how wikis work.
If the edit is bad then revert it. This is how wikis work.
If you aren't sure, investigate it, discuss it and/or tag it. This is how wikis work.
About three-quarters of the articles currently tagged as possible AI output were tagged by me. You do not have to explain to me how tagging works.
With LLMs, you do actually need to know the source to get a complete sense of what really needs "polish." A lot of the undetected AI writing we have was actually pretty damn obvious as unedited LLM text when originally added to articles in 2023-2024, but people/bots did some minor copyedits without realizing the reason why those copyedits were necessary. Which means they probably didn't check for hallucinations or mismatched references, since the need to wasn't even on their radar. Gnomingstuff (talk) 15:38, 5 September 2025 (UTC)[reply]
The problem is as well, people believing that they can just add this stuff because we don't make it clear that they shouldn't or under what conditions they might be able to. Selfstudier (talk) 17:55, 5 September 2025 (UTC)[reply]
@Gnomingstuff, can you tell me more about With LLMs, you do actually need to know the source to get a complete sense of what really needs "polish"?
If I'm looking at a sentence that says something like "Alice Expert's acclaimed book, The Sun is Very Big, enhanced her significance as an author and gives a fascinating glimpse into the rich history and evolving identity of the Sun, which stands as a vibrant symbol for so many people and cultures around the world[1]", are you saying that I need to read the cited reliable source to figure out what's wrong with the sentence, or are you saying that I need to see the un-copyedited original addition of the sentence?
I'm pretty sure I could cut that purple passage down to Alice Expert wrote a book called The Sun is Very Big[1] without needing to look at any sources. And the more you personally know about the subject matter, the less you would need to do any research to identify hallucinations. WhatamIdoing (talk) 22:43, 6 September 2025 (UTC)[reply]
You need to make sure that Alice Expert actually did write a book by that title, but also that the source it's cited to actually exists and has the same author/publication date/ISBN/URL/etc. as the article says it does, and that the source it's cited to actually mentions the fact that Alice wrote the book. All of these are things you can reasonably expect a human writer to have already done if they've added a cited statement, but with an LLM all bets are off. (Edit: Also that the text isn't a copyvio/overly close paraphrase) Gnomingstuff (talk) 01:14, 7 September 2025 (UTC)[reply]
Can you please stop condescendingly explaining things to me that are obvious?
Obviously all those things need to be done. The tendency, though, is to assume that if a piece of text looks polished and has a citation, then those things already got done. Without an LLM, the only reason a totally fabricated source and nonexistent URL would make it into an article is if the editor was inserting a deliberate hoax. Gnomingstuff (talk) 15:53, 7 September 2025 (UTC)[reply]
Apparently I do need to remind you how to suck eggs, because your comments keep implying that you have forgotten how. If you don't know the user well enough to trust that they are not vandalising the article then you should be checking all those things anyway. LLM use or otherwise is completely irrelevant. Thryduulf (talk) 16:07, 7 September 2025 (UTC)[reply]
I tend to agree with Thryduulf: "Did Alice actually write that book?" is something that has to be checked regardless of whether I think the purple prose came from a human or from an LLM.
There are several options:
I happen to already know that Alice wrote this book, so I might not bother checking the source, or even care if there is one. (Source–text integrity is valuable, but readers rarely read the sources, so it's about 300x as important to get the article text right than to worry about the cited source.)
I happen to already know that Alice writes books like these, even though I haven't heard this specific title before, so I might quickly fix the text and decide to skip checking the source because my time is limited, and I believe that it's highly likely that the facts are correct. "She wrote a book titled ___" is technically an inline citation to the book as a primary source anyway.
I don't know anything about this subject, in which case I'll fix the text and check the source.
I don't know anything about this subject, but I think you are coming from one of the cultures were purple prose is normal, in which case I'll fix the text and probably check the source.
I don't know anything about this subject, but I know and trust you, in which case I'll fix the text, check the source, and report your account as being possibly compromised, because no Wikipedia editor I trust would actually put that kind of purple prose in a live article.
I tend to disagree with Thryduulf. As Gnomingstuff says, there is an assumption that in a regular article, the claims are verified by real sources – people usually don't go to the trouble of making up references to support their unsourced claims. When sourced text is written by a human, the human is aware of what they're doing, and presuming they're editing in good faith, the claims should be verified by the sources, assuming the editor is at least somewhat competent. When the text is LLM-generated, on the other hand, and blindly pasted into the article, that good-faith-human assumption vanishes, because the text was generated by an LLM that doesn't understand what it's writing in the way that a sentient human does.
"Did Alice actually write that book?" should be checked regardless of the source, yes. But we all have limited time and we can AGF that most editors with a modicum of experience are writing articles correctly, unless we have reasonable suspicion otherwise. (Templates like {{fv}} exist for a reason, after all). But we can't AGF an LLM, and since they hallucinate so much, everything needs to be in practice scrutinized whereas most human text needs to only be theoretically scrutinized. This is why LLM editing is a bad idea, obviously.
I also agree with Gnomingstuff that Thryduulf's hostile tone to other editors in these LLM discussions is a little out of hand. God knows I get testy myself, but I don't think telling editors that I do need to remind you how to suck eggs, because your comments keep implying that you have forgotten how ([10]) or dismissing other editors' opinions as rabid and then doubling down on the childish insult ([11]) is exemplary conduct, especially from an administrator. Cremastra (talk·contribs) 18:13, 7 September 2025 (UTC)[reply]
I do try and keep my cool, but when I have to point out the same basic factual errors, assumptions of bad faith, misinformation, reading comprehension failures from the same editors multiple times it gets to the point that it's rather difficult to assume competence from one's fellow editors. Thryduulf (talk) 19:00, 7 September 2025 (UTC)[reply]
Please try to engage with the discussion. Cremastra's comment is pointing out that there can be no good-faith assumption regarding AI text. Sure, we assume that a naive copy-paste of AI text is done by a good-faith person, but such an action fails the competence test. The real question is whether there are sufficient editors able to spend hours researching AI references. Johnuniq (talk) 02:35, 8 September 2025 (UTC)[reply]
Repeatedly pointing out how and why your arguments are factually incorrect is engaging with the discussion. AI use is not, on its own, evidence of faith (good or bad) because an AI can be used in good faith and an AI can be used in bad faith. My point in this part of the discussion is that we don't need rules specific to AI when we already have rules that cover both AI and humans (without it mattering which it is). WAID explains it well - if you don't know a user and/or the source well enough to know whether an edit is likely to be correct then you should be checking to see if it is, regardless of what tool they did or did not use to make the edit. Thryduulf (talk) 04:03, 8 September 2025 (UTC)[reply]
It is not possible to partake in a discussion with people who consistently make arguments that are factually incorrect and present misinformation as truth without describing such arguments as wrong. Thryduulf (talk) 09:47, 8 September 2025 (UTC)[reply]
I mean, if we're talking about "factually incorrect arguments" and "reading comprehension failures," I never said that people who use AI are automatically editing in bad-faith. Nor do I approach people using AI under the assumption that they're editing in bad faith, because in my experience that usually isn't true.
I don't know what else to say about the res of this that hasn't already been said, repeatedly, by others. Yes, people should be checking every edit. In practice, there are over 1 billion of those. It is not feasible for every editor to check 1 billion diffs; triage must be done. So, it makes sense to prioritize edits made with the assistance of tools that are known to fabricate information or sourcing.
As far as it being more important for a statement to be right than to be correctly attributed to the source, that may be your opinion, but it's the near-exact opposite of WP:V (and only "near"-exact because they got rid of the "verifiability, not truth" wording). Gnomingstuff (talk) 15:46, 8 September 2025 (UTC)[reply]
{outdent}
It's true, Gnomingstuff, that you never said that people who use AI are automatically editing in bad-faith (as far as I know). But:
(a) you are not the only person who talks about AI users, and some of them seem to be struggling with the concept. So, starting with the first sentence of WP:AGF, let's analyze this:
Assuming good faith (AGF) means assuming that people are not deliberately trying to hurt Wikipedia, even when their actions are harmful.
Does AI use, especially in discussions, hurt Wikipedia? Maybe it does. For example, maybe it's very irritating, so I become reluctant to read discussions. Maybe it is verbose, and long comments (like this one!) get banned. But other things also hurt Wikipedia, like not pointing out a factual error in the article because you're not sure how to explain it in English. Using AI in a discussion might be a lesser-of-two-evils situation.
Does the use of AI mean that the editor is deliberately trying to hurt Wikipedia? No (or at least so rarely that it's probably not worth mentioning). Therefore, using AI is not bad faith.
(b) why are we talking about good-faith editing at all? I think your point about triage must be done is the key. Stop worrying about whether it's good faith, bad faith, or agnostic. Start asking yourself: How should I prioritize reading and responding? Mightn't it be more important too look at tools that reduce duplication of effort (ten people check this edit, but nobody checks the next edit)?
Against. There is a fringe of AI supporters and a fringe of knee-jerk reactionaries but most editors are generally against AI's usage and highly skeptical of it. Cremastra (talk·contribs) 06:42, 3 September 2025 (UTC)[reply]
I have a window somewhere with another dozen discussions to add to that table, plus all the ones that happened since then. I'd love it if someone else would work on that. WhatamIdoing (talk) 03:07, 4 September 2025 (UTC)[reply]
I wish there was an easier way to add things to tables in the project space (using the source editor to do that is a pain imo). Maybe dump the list of links on the talk page and when editors are bored, they can add them. Some1 (talk) 18:02, 5 September 2025 (UTC)[reply]
Thanks, I didn't realize people could edit the Wikipedia namespace with Visual editor; I only see the "Edit source" (and not the "Edit") button at the top of these Wikipedia:[...] pages. Good to know! Some1 (talk) 00:13, 7 September 2025 (UTC)[reply]
When discussion has ended, remove this tag and it will be removed from the lists. If this page is on additional lists, they will be noted below.
Should a bot be used to fix linter errors and fix Vector 2022 dark mode on old Articles for Deletion subpages? 16:46, 9 September 2025 (UTC)
Please read this RfC before commenting here. I (Matrix) am proposing a bot to fix dark mode on old AfDs, please read the proposal at the BRFA and comment here whether you support or oppose it.
@Pppery: Chaos? Firstly, unlike the above RfC which made millions of edits, this is limited to the WP namespace, so no "user talk was edited" notifications will go off. Secondly, there's a reason the bot flag was created, which was to help you hide stuff in watchlists and stuff like that. —Matrixping mewhen u reply (t? - c) 19:13, 8 September 2025 (UTC)[reply]
(I'm copying this from the BRFA) "The question isn't the number of people who use dark mode, it's the intersection of the number of people who use dark mode and who visit old AfDs, and the latter set is pretty small in the first place. And you surely know already that large bot tasks inevitably cause people to complain as they are happening." (from Pppery) —Matrixping mewhen u reply (t? - c) 19:17, 8 September 2025 (UTC)[reply]
@Pppery: People scrolling through AfD archives are more likely to have dark mode on, because they are likely power users and power users want all the new features. Besides, we're fixing lint errors along the way. —Matrixping mewhen u reply (t? - c) 19:34, 8 September 2025 (UTC)[reply]
I'm someone who is often regarded as a "power user". I use Monobook skin in light mode and, when I use the source editor (roughly 50% of my edits) I use the 2010 editor. Most "power users" will use whatever tool is the most powerful which is not necessarily the most recent - indeed in many cases the most recent tool is often less powerful because it has been simplified for the benefit of those who are not power users. Whether someone prefers light or dark mode is likely something that is completely independent of whether they're a power user or not. Thryduulf (talk) 01:02, 9 September 2025 (UTC)[reply]
And many other power users will, like me, keep using what they're used to and already have set up how they like it if they don't need any of the new features, instead of changing and having to relearn how to do all the things in the new interface. Anomie⚔13:52, 9 September 2025 (UTC)[reply]
Perhaps, but turning on the bot flag when there's a large activity in the spaces we edit means we're not only missing less frequent bot edits we might want to see, but also are missing recent living creature edits that were immediately followed by a bot edit, as the watchlist system will sometimes not display the human edit when that happens. As such, it's best to avoid the mass edits unless they are necessary. -- Nat Gertler (talk) 19:44, 8 September 2025 (UTC)[reply]
@Izno: we're also fixing lint errors in this task as well, which has no workaround except fixing. And while we're fixing the lint error with color: inherit, we might as well convert the background color to the new dark mode one. —Matrixping mewhen u reply (t? - c) 19:36, 8 September 2025 (UTC)[reply]
The relevant workaround being the one that targets [style~=background]? I'm the one who suggested that bit of CSS one fateful day several years ago to a relevant engineer as the dark mode effort was beginning to ramp up. I don't see trying to remove the need for that CSS as useful (at this time, perhaps) as there are many many other places that rely on it besides 500k pages worth of archives.
@Izno: we need to move away from relying on that CSS rule, which is why I am suggesting this. We don't need to remove the rule, but just reduce reliance on it, as it is quite crude. This is one step at that. —Matrixping mewhen u reply (t? - c) 22:48, 8 September 2025 (UTC)[reply]
Oppose per Pppery and Nat Gertler. Editing archives should only ever be done when the edit makes a substantial improvement to the project in some way. Making nearly half a million edits just so that a bit of form text that appears on >90% of AfDs is slightly more visible to the tiny number of people who read old AfDs while using dark mode is so far below that bar it's ridiculous. Even fixing lint errors fails to reach the bar most of the time and this is significantly less useful than that. Thryduulf (talk) 20:46, 8 September 2025 (UTC)[reply]
A lint error that only appears in dark mode? You really need to do better to explain why this should be "fixed" and why it is worth doing more than 50 edits. —Kusma (talk) 22:19, 8 September 2025 (UTC)[reply]
@Matrix, if this is a lint error worth fixing then there will be consensus for the lint error fixing bots to fix it. You will also note that I said Even fixing lint errors fails to reach the bar [where editing archive pages is beneficial to the project] most of the time and this lint error is especially low value. Thryduulf (talk) 00:57, 9 September 2025 (UTC)[reply]
@Pppery: Considering this is a very technical topic it is necessary to explain a bit more - that is not bludgeoning and is actually constructive towards consensus. I only responded to like 3 comments anyway, and I don't expect to change anyone's view if they are opposed. See Wikipedia:Encourage full discussions. —Matrixping mewhen u reply (t? - c) 16:23, 9 September 2025 (UTC)[reply]
Support I don't use dark mode myself but looking at the before and after examples linked on the BFRA, it improves things for those using dark mode. Also, doesn't hurt things for anyone not using dark mode, so don't see any reasons not to. If someone is willing to do those changes then why not. -- WOSlinker (talk) 21:28, 8 September 2025 (UTC)[reply]
Support per WOSlinker and what Primefac said on the BRFA. It doesn't really hurt anyone, those concerned about watchlist spam can just configure their settings to ignore bot edits. Tenshi! (Talk page) 22:13, 8 September 2025 (UTC)[reply]
er, what is the improvement being made? It looks pretty much the same to me (at least in Monobook Dark mode) so oppose unless it is clarified what the point is. —Kusma (talk) 22:15, 8 September 2025 (UTC)[reply]
Support: I don't personally think linter errors are a huge priority, but that doesn't mean others should be prevented from fixing them. The set of people who have old AfDs on their watchlist for some reason and could possibly be inconvenienced is probably as small, if not smaller, than the set of people who view old AfDs in dark mode. Gnomingstuff (talk) 23:22, 8 September 2025 (UTC)[reply]
I am in generally in support, but if you're going to make this many edits I'd like to see a deeper investigation of what other kinds of issues can be fixed at the same time. Also seems like it would be more worthwhile to replace it with a template so we don't need to make a second pass if other issues are discovered in the future. Legoktm (talk) 00:08, 9 September 2025 (UTC)[reply]
@Legoktm: that would be a good idea, but if we did that we would also need to do the same thing for all XfD discussions, plus all RMs, most {{atop}}s, etc. Not to mention the massive technical issue of fixing nearly every single anti-vandalism tool. I don't think that's worth it. —Matrixping mewhen u reply (t? - c) 16:25, 9 September 2025 (UTC)[reply]
I don't think we need to decide the fate of literally everything now just to improve AfD archives, it can be an iterative process. I also don't see why anti-vandalism tools need to be fixed, why would they even care about this formatting change? Legoktm (talk) 17:55, 9 September 2025 (UTC)[reply]
If we use a template now, don't we have to use the template in the future? I feel it would be inconsistent to sometimes use a template and sometimes subst stuff. —Matrixping mewhen u reply (t? - c) 18:27, 9 September 2025 (UTC)[reply]
I was going to make this an RfC from the start to avoid LOCALCONSENSUS issues, but forgot. Also as proposer and the person who made the BRFA, I support obviously. —Matrixping mewhen u reply (t? - c) 16:46, 9 September 2025 (UTC)[reply]
Support. I really don't see any downsides to this. But, as someone who regularly reads old AfDs, sometimes uses dark mode, and generally appreciates that linter issues can be important in the long run, I think there would be significant benefits. Toadspike[Talk]06:54, 10 September 2025 (UTC)[reply]
Oppose: Similar to WP:RAGPICKING: we all have better things to do than make miniscule formating tweaks to old pages for a minority of users. If hundreds of editors were coming forward and saying "I use dark mode and this is a real pain", then I'd support. But I'm not seeing that. I honestly don't understand what a lint error is, but this one seems to be pretty minor (replacing standard inline CSS with something complicated). Cremastra (talk·contribs) 20:21, 10 September 2025 (UTC)[reply]
Full Support: Accessibility improvements should never rejected on the basis of "it inconveniences my watchlist" or "I don't use this feature", it should pass or fail on the merits and benefits of the task proposed and the proof of the task will address the issue as intended with minimal to no error rate if run. To those complaining about "well, it don't look broken in light mode", this task isn't for fixing something in light mode and will not affect your light mode viewing, this is for fixing a glaring problem in dark mode that makes viewing AFDs in dark mode problematic. The claims of "well, I don't use dark mode, don't run this task" are an injustice to users who do use dark mode who have to endure being blinded on AFD pages from these sections not displaying as they should. If Wikipedia offers different viewing modes, all pages should work and display correctly in all modes.To highlight the proposed change in a visual manner so that there's no question what this task is changing, This -> https://i.imgur.com/Fch83DD.png is an AFD page in dark mode with no changes and is a prime example of this error. The page should NOT be mostly white in dark mode, it should be uniformly dark and comfortable to view without feeling like you are staring at an approaching car's highbeams at night. After this task runs, it would look like this -> https://i.imgur.com/Gw40Qfc.png for dark mode users and behave as it should. The suggestions of "just use light mode, there's no issues here" are as obnoxious as me stating to you "Dark mode is only a few clicks away, why aren't you using it as it's easier on the eyes"?... We both know we have reasons for picking light mode or dark mode as our mode of choice, and we just want pages to display correctly as much as you do with as minimal bother to you as possible. This is a small step in the equal display direction.Additionally, ditto WOSlinker, Primefac, and Legotkm's comments about can we fix anything else in this run to minimize the AFD pitchforks, and why isn't this a template we transcribe? Seems problematic that it isn't due to standard "woe is my watchlist" kerfuffle whenever corrective tasks regarding AFDs are mentioned. Zinnober9 (talk) 21:28, 10 September 2025 (UTC)[reply]
Support per Zinnober9. Further to Legoktm's point, I would support adding __NOINDEX__ to all AFDs while we are at it. We discovered that our attempt to do this site-wide is not working last December, but we didn't actually come up with a plan to fix it. I think the idea of transcluding a template (maybe just add {{AFD help}} where it is not already present?) is a great one, so we can easily make updates if needed in the future. Don't want to spend time on this? You don't have to code the bot or worry about what it will do. HouseBlaster (talk • he/they)01:29, 11 September 2025 (UTC)[reply]
In case people wonder why robots.txt does not work, from Google themselves: Don't use a robots.txt file as a means to hide your web pages... If other pages point to your page with descriptive text, Google could still index the URL without visiting the page.– robertsky (talk) 03:57, 11 September 2025 (UTC)[reply]
Support although it should be noted that the only thing that needs to happen is "unblending" i.e. figuring out which color mixed with white in which alpha amount results in the resulting color. These are very minor but important changes to improve legibility in dark mode. Aasim (話す) 21:00, 11 September 2025 (UTC)[reply]
Creating a separate discussion, since a lot of supports seem to be stating that I should replace the whole thing with a template, rather than just changing the CSS values. Any input is appreciated —Matrixping mewhen u reply (t? - c) 17:08, 11 September 2025 (UTC)[reply]
Neutral as original proposer. I don't have any strong views on this, and am willing to do whatever the community's view on this is. —Matrixping mewhen u reply (t? - c) 17:08, 11 September 2025 (UTC)[reply]
Ok, no one replied to this; there are a few other tasks that can be done on the journey, what's the consensus on doing those as well?
"un-subst" the template, so that future edits can be made at once, rather than on all ~495K pages
add NOINDEX to prevent indexing by search engines (because apparently robots.txt doesn't work)
Support unsubst (so we don't have to do this ever again) and support NOINDEX (while we can argue about the efficacy of dark mode fixes, I hope we can agree that NOINDEXing discussions, including those about BLPs, is a worthwhile pursuit). Probably a better idea to just unsubst and then do the dark mode and NOINDEX fixes in the unsubsted template. HouseBlaster (talk • he/they)20:47, 18 September 2025 (UTC)[reply]
Support both as generally good ideas. I can see no reason a boilerplate header/footer that could foreseeably need updating should be substed every time, and these pages do not need to be indexed. Toadspike[Talk]20:52, 18 September 2025 (UTC)[reply]
Support switching to the template in general, I don't have the relevant context on NOINDEX so I'll abstain from commenting on that. In general I disagree with Pppery that doing some cleanup isn't worth it just because the task is significantly large (I appreciate people who are willing to take on such gargantuan tasks!). Legoktm (talk) 00:41, 19 September 2025 (UTC)[reply]
I Support replacing the boilerplate with a template after a sufficient set of demonstration edits on AfDs from many different years. I have found while editing (far too many) AfD and similar pages to fix Linter errors that there are sometimes subtle variants on these bits of text that one presumes would be identical. Also, the boilerplate text sometimes gets edited after it is placed. It might take a few runs to find the variants, and a bot task might only be able to handle 90+% instead of 99+% of them. Ideally, they won't contain elements that need different template variants to replace them. – Jonesey95 (talk) 21:12, 18 September 2025 (UTC)[reply]
So are you saying that you support the unsubst that would eliminate future needs to updating AFD pages directly whenever these boilerplates need an update in future years? Or are you rejecting any and all bot tasks on any AFD page? Please clarify your ambiguous statement. Zinnober9 (talk) 22:19, 18 September 2025 (UTC)[reply]
I don't see the ambiguity here; but to restate my position, I reject any and all bot tasks that would require editing all hundreds of thousands of AfDs (or pretty much hundreds of thousands of pages of any kind as a one-time run; note I also opposed the reflist bot above). * Pppery *it has begun...04:20, 19 September 2025 (UTC)[reply]
Skimming through some very old discussion archives, I've come across a few mentions that now go against WP:Don't worry about performance and others that are similar to what Thryduulf mentions below in saying opposed to boilerplates not being substed going forwards because care will have to be taken to ensure that changes don't state or imply things that were not true at the time of old AfDs. There may be other discussions I haven't found. Anomie⚔02:21, 19 September 2025 (UTC)[reply]
Personally, so far I'm leaning towards an oppose on the unsubsted template idea based on the "historical record" point. I'm not much caring about fixing versus not-fixing the inline CSS in the archives, since I doubt both that many will care that much about old AfDs while not being able to work around the possible contrast issue and that many will be paying enough attention to the old AfDs that a bot going through them actually matters (as long as we don't get another MalnadachBot situation). Anomie⚔02:21, 19 September 2025 (UTC)[reply]
I continue to oppose these essentially cosmetic changes to old AfD pages because the value of them is multiple orders of magnitude lower than the disruption the bot will cause (and regard this discussion following the extensive objections above to be rather tone deaf at best). I don't necessary oppose all future changes to old AfD pages, because I don't know what those changes will be, but will oppose any others that don't provide benefit to the project above and beyond the disruption. I'm weakly opposed to boilerplates not being substed going forwards because care will have to be taken to ensure that changes don't state or imply things that were not true at the time of old AfDs. For example if a new rule required everyone who had contributed to the article being discussed to explicitly disclose that, and this was added to the boilerplate, it would be misleading for that to appear on discussions from before the rule was introduced. Thryduulf (talk) 22:33, 18 September 2025 (UTC)[reply]
I do not support replacing <spanstyle="color:red;">'''Please do not modify it.'''</span> with a template. There isn't much value in trying to make this particular message more legible, and with banner blindness, most people will never pay any attention to it.
I am more ambivalent about changes to specify the background colour, whether that is by introducing a template, or changing the hardcoding. In principle I think it is a good idea to make all pages follow dark mode standards. But I understand that churn to so many pages can be unappreciated by those most involved in the articles for deletion process. The gentler approach is to just continue with new discussions supporting dark mode, and at some point in the future, when the discussions supporting dark mode are the large majority, consider if a change should be made then. isaacl (talk) 23:28, 18 September 2025 (UTC)[reply]
Support transclusions per Jonesey95. Substituting these has never made sense to me, and doubly so in regards to the ubiquitous AFD pitchforking. If someone knows why they were substituted, then I'm open to considering the merits of that reasoning. But converting to transclusion would reduce the future bother to the Afd community from the known knowns at hand so far in this AFC. I agree that variants (if any) should be identified, and any variants' adjustments retained. I'm Indifferent on the Noindexing. I don't have a grasp on the ins and outs of that at this point to have a strong vote, but I don't object. Overall I think we all agree that the AFDs should be left alone as much as possible, but how or to what point looks to be the meat of this discussion. Zinnober9 (talk) 00:13, 19 September 2025 (UTC)[reply]
Amending the global rights policy regarding temporary account IP access
Various global groups, e.g. global rollback, global abuse filter helper, steward, abuse filter maintainer, and ombuds, have the technical ability to view temporary account IP addresses. This is in addition to administrators and temporary account IP viewers.
I'm here to raise the following question:
Should the global rights policy be amended to explicitly allow or prohibit the use of global rights to access temporary account IP addresses?
The holders of these global rights have the need in their work on the global level though. If anything the language in our local policy may be refine to discourage the use unless necessary locally. It is already there but in bits and pieces. – robertsky (talk) 04:01, 11 September 2025 (UTC)[reply]
Anybody who has it globally already fits the spirit of demonstrated need guidelines. GRs, GSes, Stewards and CUs of other wikis are the typically the ones who have this right and it would be rather short-sighted to assert that they do not have a demonstrated need for WP:TAIV. Sohom (talk) 12:57, 11 September 2025 (UTC)[reply]
We don't grant the right automatically to editors with equivalent rights on en-wiki. And I disagree every global userright has a demonstrated need on en-wiki. A global sysop, for example, has no need to use any of their tools here, let alone one that provides access to information the WMF has deemed private. voorts (talk/contributions) 13:01, 11 September 2025 (UTC)[reply]
Cross-wiki LTAs come to mind, if they cannot very the TA is the same IP underlying here, how will they mark a page for deletion? (note not deletion, because they cannot use their rights here) Sohom (talk) 13:09, 11 September 2025 (UTC)[reply]
It seems like the question is: Should global users, that already have global access to view temporary accounts, be allowed to use this permission here? - in which case, yes - they should. Accounts, including temporary accounts, are global - making these users go through a paperwork exercise to get a local group for this is excessive. — xaosfluxTalk13:08, 11 September 2025 (UTC)[reply]
Note, the largest "outside" users here are the global rollbackers and the global temp viewers (which are mostly checkusers/oversighters from other projects). — xaosfluxTalk13:22, 11 September 2025 (UTC)[reply]
Those are good examples. Maybe giving concrete examples would help people out. For example:
A WP:Global rollbacker is a person who does anti-vandalism work across wikis. Sometimes that work will require (e.g.,) being able to see the IP address of Wikipedia:Temporary accounts (basically logged-out/IP editors, except with their IP addresses no longer being permanently listed in plain text in the article's history page). If a global rollbacker is undoing a bunch of cross-wiki vandalism by a temp account/IP editor, do we want them to:
have access to the IP information, so they can find and revert vandalism here, too, or
skip the English Wikipedia, because we can do everything ourselves and don't want their help.
We should not limit IP viewing by global rights holders at the moment. IPs are currently open to the world, but the plan is to hide them from many, many people. Let's not overshoot by making cross-wiki vandal fighting harder without actual evidence that the new restrictions are insufficient. —Kusma (talk) 20:31, 11 September 2025 (UTC)[reply]
Global rights holders should be allowed to view TA IPs if they have the technical ability to do so. Everyone with such a userright has a "demonstrated need". By the way, do any of those groups have "checkuser-temporary-account-auto-reveal"? That userright would make it impossible for us to disallow them from viewing TA IPs without a global RfC/change. Toadspike[Talk]19:49, 16 September 2025 (UTC)[reply]
Thanks. In that case this discussion is moot, as there is literally no way we prohibit editors using that tool here other than 1. blocking them from enwiki (though I'm not even sure that would work? I think you can still see RecentChanges when blocked etc.) or 2. amending the userrights to remove autoreveal. We also cannot grant autoreveal via the PERM process, so there's no way for individual global rights holders to "rectify" any discrepancy except by RfA. Anyhow, I stand by my position that their use of these userrights on enwiki is okay without a local perm grant. Toadspike[Talk]13:23, 17 September 2025 (UTC)[reply]
Request for feedback on proposed policies regarding the use of banners and logos for advocacy purposes
Informed by research conducted earlier this year, I have proposed some draft policies that would affect the procedures communities use to engage in advocacy using banners and logos. The proposals include a new policy on the use of Wikimedia sites for advocacy purposes, as well as additions to the CentralNotice usage guidelines and to the process for requesting wiki configuration changes. You can review the policies and provide feedback through October 9 at Meta-Wiki's Wikimedia Foundation/Legal/Update to banner and logo policies. Thank you!
DownBeat critic Carlo Wolff describes the album as "contemporary chamber music of power and persuasion, that joins its musicians in a quest for serenity". AllMusic critic Thom Jurek referred to it as "sophisticated and spiritually resonant". Jazz Journal critic Simon Adams stated "It's often dangerous to over-praise a set, but in its quiet, understated way, I would call this album faultless. Modern jazz chamber music at its finest." Jazzwise critic John Fordham states "Drifting may remind you of a dream, or an embrace, or a preoccupied woodland wander a lot more than a wild bop-blasting night in a jazz club, but that's what the unique Mette Henriette is all about."
Note that Carlo Wolff and John Fordham are wikilinked, while Thom Jurek and Simon Adams are not. This seems odd.
So, I'm wondering if there's been discussion of this, either here or elsewhere, with some consensus.
The MOS:LINK article doesn't seem to be dispositive, saying that we should wikilink Relevant connections to the subject of another article that help readers understand the article more fully - I'm unconvinced that linking to AllMusic or Carlo Wolff for example does much to help the reader understand a particular recording. OTOH, it also says to wikilink Proper names that are likely to be unfamiliar to readers. which argues for linking all of the critics' names. Mr. Swordfish (talk) 15:33, 13 September 2025 (UTC)[reply]
If they have articles they should be linked. If they appear notable but lack an article they may be red linked. If they do not appear notable and lack an article they should not be linked. This is not limited to music critics in any way, just how we generally deal with linking people. Horse Eye's Back (talk) 15:41, 13 September 2025 (UTC)[reply]
Ok. Thanks. I recently created a page for Michael G. Nastos and was wondering if I should wikilink every mention of his reviews. Your reply indicates that this should be done, however there are ten pages of google results that would need to be changed. Is there a script for doing this? I'm not eager to do it all by hand. Mr. Swordfish (talk) 16:38, 13 September 2025 (UTC)[reply]
I don't know of a script to do it, but it doesn't need to be done immediately or all at once. You could do a few at a time. Better to use an insource search on wikipedia (results) than google. His name is already wikilinked in a few of the articles. Schazjmd(talk)16:57, 13 September 2025 (UTC)[reply]
IMO its a WP:NODEADLINE situation, the thousand edits can either be made by you right here right now (scripte assisted or otherwise) or they can be made one at a time by dozens or hundreds of editors over the coming years or something in between. Any way is good and the important thing for me is that the article was created. Horse Eye's Back (talk) 17:01, 13 September 2025 (UTC)[reply]
I see Template:Simple has recently been placed at the top of some policy and guideline pages. Are we sure we want to direct new users to unvetted info pages off the bat like this.... that in my view are leading them to the wrong type of pages in some cases. For example at Wikipedia:Content assessment we link a readers' FAQ page Help:Assessing article quality that is designed for non-editing readers. At Wikipedia:Deletion policy a page about rationale and how to go about the process we link Wikipedia:Why was the page I created deleted? a page about what you can do about a deleted page. Not sure if these links have been well thought out. Wondering if we should have a chat before this is added to more policy and guideline pages? Linking simpler help pages from long-winded help pages make sense... I'm just not sure linking these types of pages from policies and guidelines are appropriate in the fashion that they're presented at the top of the page as if these linked pages have been vetted by the community makes sense. Moxy🍁22:31, 13 September 2025 (UTC)[reply]
Not sure merging simplified essays into policies and guidelines pages would be beneficial or pass muster. My main concern is are we and should we direct new users to loosely related essay pages from policy and guideline pages off the bat that currently stand out in big bold letters.Moxy🍁23:09, 13 September 2025 (UTC)[reply]
I've not looked at any of the examples yet, but really nobody should be adding prominent links to the top of (especially fundamental) policy pages without at least discussing it first. I don't know that it needs to be a full-on consensus discussion unless there are substantive objections, but there needs to be at least some agreement from talk page watchers that the other page is relevant, appropriate and helpful. Thryduulf (talk) 23:32, 13 September 2025 (UTC)[reply]
I don't love this, but I think this is probably not a bad thing, overall.
First, before anyone panics, this is only on about two dozen pages, and I think that it's only on two official policies:
The pages it points to are generally community favorites, and there is no reason to believe that any of these links were snuck on to the pages without anybody noticing. And frankly, in the case of pages like Help:Table (5754 words "readable prose size", except most of it is not readable by ordinary humans), most editors actually should be looking at a much simplified page. WhatamIdoing (talk) 02:11, 14 September 2025 (UTC)[reply]
I read your argument as "these linked pages are de-facto approved pages". Under that condition, of course it is fine. Maybe these simple pages should be the main pages and the current main pages need converted to specialized instructions? Johnjbarton (talk) 02:30, 14 September 2025 (UTC)[reply]
We can't really "replace" the pages. They aren't interchangeable. For example, Wikipedia:Inline citation exists to explain what an inline citation is and isn't. WP:REFB exists to help newbies figure out how to format the most popular kind. If you moved REFB at the name "Inline citation", we'd just have to create another page that explains that ref tags aren't the only kind of inline citation ...and a newbie would still end up at that page when they really just need something that says "copy and paste this wikitext", and we'd get another note at the top saying that if you're not really looking for details, then there's a simpler instruction page that you might want to look at instead. WhatamIdoing (talk) 04:16, 14 September 2025 (UTC)[reply]
This is not a good template idea, agree with Johnjbarton. Our policies and guidelines are, when not simple, not so for a reason. We should not give alternative wording official sanction unless it has this. Simultaneously, if there is an obvious way to simplify the policies and guidelines, it should be done on the actual pages. Perhaps we might link to essays that oversimplify the relevant pages, which could have some use for new users who want the basics that won't land them in trouble, but these should clearly be marked as oversimplifications. CMD (talk) 02:51, 14 September 2025 (UTC)[reply]
Relative to most newbies' needs, do you think that WP:REFB should be labeled "an oversimplified version" of anything? I think "a simplified version" is a fairer description, though "Are you new here? Start with WP:REFB" would work for me. WhatamIdoing (talk) 04:20, 14 September 2025 (UTC)[reply]
You said these should clearly be marked as oversimplifications. But you don't want us to label a link to REFB as being an oversimplification, because calling REFB an oversimplification would be a misleading lie. These statements are superficially self-contradictory, but I think you're right.
I think we have two separate questions to answer:
Do we want to have links/hatnotes/banners/templates that direct inexperienced editors away from complicated pages, towards simpler/more relevant pages?
If so, how should we describe those links? You dislike the "simplified version" language (for understandable reasons). "Oversimplified" is IMO even worse. Maybe something like "If you're new to editing Wikipedia, you may want to start at _____" would be better.
The statements are not contradictory. The first statement was a general one premised on the good faith assumption that the items under discussion being presented as simplified versions are simplified versions. The second statement relates to a specific example raised after that first statement where the item presented as a summary was not a summary but rather a general guide of a related topic. CMD (talk) 16:19, 15 September 2025 (UTC)[reply]
Just since I was pinged, yes, I do disagree with Favi doing this, but since I did not see much in the way of reverts, and they're not terrible additions, I have mostly left them be. Primefac (talk) 17:32, 14 September 2025 (UTC)[reply]
By the way, we do have a mechanism to differentiate between a random essay and a broadly accepted consensus supplement for policy/guideline pages - WP:SUPPLEMENTAL with the pages that are broadly agreed upon by the community being tagged with it and are part of Category:Wikipedia supplemental pages.
So maybe the question is whether any how-to pages that are linked at the very top of a policy guide using the {{Simple}} template should also mandatorily have been evaluated to qualify similarly for supplemental status (over just being a regular info/how-to page), since that seems to be kind of the bar for such articles that are tagged with {{Supplement}} and linked at the policy section, e.g. WP:LOWPROFILE supplement being the supplement to WP:BLP - WP:NPF - Non-public figure policy - the supplement has broad consensus and is de-facto policy on how we assess whether someone qualifies as public figure or not. Raladic (talk) 02:29, 19 September 2025 (UTC)[reply]
The following discussion is closed. Please do not modify it. Subsequent comments should be made on the appropriate discussion page. No further edits should be made to this discussion.
A large amount of Wikipedia users share their full names, images, and places of work and study on their Userpages. I find this unacceptable, not only are you putting yourself in danger you are also putting others at risk if you share info about your affiliates (One user page included a photo of the user's child). It is incredibly easy to target these people and worse when occurring on Wikipedia because of our handy Page History. Please see WP:AMDB if you need an example as to why this may be harmful. Rules need to be established as to what is allowed to be shared.
The discussion above is closed. Please do not modify it. Subsequent comments should be made on the appropriate discussion page. No further edits should be made to this discussion.
Are semi-automated edits to improve MOS:CURLY compliance okay with the community?
I'm working on a tool called WikiClicky that performs various single-character edits to improve Wikipedia articles. I have established community consensus that the grammar-correction features I've added are okay. What would the community say about edits from this tool that only serve to improve an article's compliance with MOS:CURLY? GrinningIodize (talk) 21:42, 14 September 2025 (UTC)[reply]
The following discussion is closed. Please do not modify it. Subsequent comments should be made on the appropriate discussion page. No further edits should be made to this discussion.
For accounts that were created before the deployment of the newcomer home page, the target destination when clicking on your user name on the top right is your user page. The WMF decided that to repurpose the link to access the newcomer home page, and your user page can be accessed from there. The behaviour can be configured on the preferences page: Preferences → User profile → Newcomer editor features → Display newcomer homepage. However disabling it also disables your homepage. isaacl (talk) 00:08, 16 September 2025 (UTC)[reply]
The discussion above is closed. Please do not modify it. Subsequent comments should be made on the appropriate discussion page. No further edits should be made to this discussion.
When discussion has ended, remove this tag and it will be removed from the list. If this page is on additional lists, they will be noted below.
According to the Olympstats blog, one possible estimate for the total number of people to have participated in the Olympics as of 2015 was 128,420, though as it notes other estimates could be created. It has been proposed to create a complete alphabetical listing of all participants of the Olympics, spread across a number of articles. An example of one of these lists can be seen here. FOARP (talk) 11:16, 17 September 2025 (UTC)[reply]
Oppose - The possible number of entrants makes this essentially a phonebook, something which Wikipedia is clearly WP:NOT. It would not be useful for navigation because of its length - a figure that is not even fixed but grows by thousands with each edition of the summer and winter games. FOARP (talk) 11:16, 17 September 2025 (UTC)[reply]
This says "this RFC was recommended in the close here". Where was this RfC recommended in the admin's close? The only time an RfC was mentioned by the closing admin was as as an aside "...and I believe the intersection of lists of sportspeople with NOTDB is ripe for a community-wide RfC". Creating an RfC focused on one specific list to exist or not, as this is, feels like circumventing the AfD process just one day after an AfD on this list was closed. I wouldn't oppose a broader RfC on "the intersection of lists of sportspeople with NOTDB", but it can't be phrased in this way about one specific list that both you and I were WP:INVOLVED in the AfD for. (also, why wouldn't you use the first page as an example of the list contents?) --Habst (talk) 12:07, 17 September 2025 (UTC)[reply]
So that this isn't just an exact re-hashing of the AfD closed one day ago, I proposed adding additional options:
Oppose lists:
Oppose having any list of Olympians
Oppose specifically an alphabetic list, open to others
Support having a list in some form:
Support keeping existing Olympic list (alphabetic)
@Habst the diff of the reversion is actually Special:Diff/1311888941. I think the additional nuance is useful and won't overwhelm the discussion - indeed I think it's likely to aid the finding of a consensus and avoid the need for more future discussions. Thryduulf (talk) 14:26, 17 September 2025 (UTC)[reply]
Oppose A full alphabet listing of Olympians is not a natural sorting order for them, so it doesn't make sense to make such a list. (Olympians by country or by sport are far more natural). This is also where categorization is already set up to do that. Masem (t) 12:11, 17 September 2025 (UTC)[reply]
Neutral. At AfD I said that these clearly meet NLIST, and they do. But whether they are worth having around is a separate question, hence why this RfC is a good idea. I think arguments on both sides are sensible, so I land at a neutral or weak support. These lists technically fall within policy, but I'm not fully convinced that they're useful to readers. Toadspike[Talk]12:59, 17 September 2025 (UTC)[reply]
Support a list of all Olympic competitors is very clearly useful and satisfies NLIST as they are discussed as a group and the inclusion criteria is not indiscriminate. Such a list would be impossible to navigate for size reasons though, so it needs to be split and alphabetic is self-evidently one logical method of doing so. Wikipedia is not paper so we don't need to worry about the number of articles, and the existence of these listings does not preclude the existence of other splits (e.g. by games or by nationality). Thryduulf (talk) 13:24, 17 September 2025 (UTC)[reply]
To clarify now additional nuance has been requested above, I support the existence of lists organised alphabetically, by nationality, by games and by sport. I'm presently neutral on other lists. Thryduulf (talk) 13:27, 17 September 2025 (UTC)[reply]
The maintenance burden for these lists would be pretty high. Every Olympics, someone would have to go add them all in alphabetical order, interspersed. Perhaps grouping by Summer/Winter Olympics Of Year XXXX would make more sense, instead of a massive alphabetical list? –Novem Linguae (talk) 15:00, 17 September 2025 (UTC)[reply]
As Perryprog alludes to, there are so many different ways to organize the data and the data is constantly being updated, so a database sorting/filtering interface is more suitable than creating snapshot lists of all possible organization methods. Even if the snapshot process were automated, the length of the lists makes them unwieldy for convenient use. I think better search tools (either based on Wikipedia or Wikidata) would be a more extensible, manageable solution. isaacl (talk) 16:06, 17 September 2025 (UTC)[reply]
In my AfD closure I recommended that the community discuss the intersection of lists of sportspeople and WP:NOTDATABASE, or possibly the interpretation of NOTDB as it applies to large groups with well-defined inclusion criteria more broadly. There is a clear divide in the community as to the interpretation of NOTDB in this context. I didn't intend to recommend an RfC about this list specifically. I cannot preclude one, of course, and as I closed the discussion, and am genuinely undecided, I won't be commenting on the merits. Vanamonde93 (talk) 16:21, 17 September 2025 (UTC)[reply]
Oppose Also agree with User:FOARP that this is basically a phonebook given the sheer length. It's not useful for navigation particularly: who knows only the first letter of an olympians name, and nothing else, and needs to find them? What about "List of olympians in snowboarding" or topic-based lists? Those might be more useful. Mrfoogles (talk) 01:10, 18 September 2025 (UTC)[reply]
Oppose This list is fundamentally a bad idea for several reasons. WP:NOTEVERYTHING shows an existing consensus that databases and phone lists are not appopriate on Wikipedia. Secondly, discussion at AfD revealed that the collation was manuallyy sourced and created from wikidata. But if that is so, then we already have the collection in wikidata. This is just bad information management, to create two copies of the data that require manual intervention to prevent them falling out of step with each other. And thirdly, that workload is excessive and the reason that wikipedia lists, in general, are not useful if they claim to be exhaustive: because they are not. They rely on diligent and continual editor resource, that they cannot ever achieve. As FOARP points out, the enormous size of this list, and the speed at which it accrues new entries will guaranty that the list will be incomplete, and bad data is worse than no data. Fourthly, in this format, the data is unusable. If you know the name of someone you want, search is faster, as is querying wikidata. If you don't, then this list is not a suitable taxonomy. Fifthly, we already have the means for creating taxonomies, and those taxonomies already exist in the form of existing categories. So no, we shouldn't do this. We should use the existing wikidata and categories, and if anyone is interested in some kind of searchable list - dynamically generate it from wikidata. Sirfurboy🏄 (talk) 07:33, 18 September 2025 (UTC)[reply]
Actually, those categories do not contain every Olympian. There is no other place (whether categories, wikidata, or even other websites) for anyone to find a complete listing of Olympians. BeanieFan11 (talk) 16:50, 18 September 2025 (UTC)[reply]
To clarify, I support having this information, I just think there is probably some better way of organizing the data that would make it more accessible to readers than an arbitrary number of alphabetized lists. mdm.bla17:18, 18 September 2025 (UTC)[reply]
Oppose These articles are too long and have too little information to be useful. They also clearly violate the spirit and probably the letter of the law that Wikipedia is not to be a directory. Some have argued that there is sourcing about Olympic competitors as a group. This sourcing is on the general trends of who has been Olympic competitors, but with an unclear number somewhere around 150,000 or 160,000, it is not possible to create a comprehensive list and sources do not do this, just cherry picking some sub-group, or what they find interesting or excited cases. We maybe could have an article Olympic competitors or the like that says things about Olympic competitors as a group, maybe subdivided in some ways, but sourcing does not justify creating a directory of every single Olympic competitor whose name we know, especially one that really does not tell us much about the individuals. I do not think creating such a massive directory of Olympic competitors is within the listed things Wikipedia is, and I do not think there are sufficient reliable sources to support such a directory in Wikipedia.John Pack Lambert (talk) 21:37, 18 September 2025 (UTC)[reply]
What is it we're looking to do here? The framing is odd -- It has been proposed to create, and a focus on supporting/opposing creation as though the articles don't already exist. It just went through AfD, which ended in no consensus, and an RfC on retroactive opinions on creation (?) isn't a substitute for that process. Opposition to creation doesn't necessarily mean support for deletion (and vice versa), and the choice here doesn't include deletion. If you're trying to establish a precedent about the scope of a list, this also doesn't do that, because it's too focused on a specific example. — Rhododendritestalk \\ 14:46, 17 September 2025 (UTC)[reply]
Thank you. To be honest, I'm feeling this RfC is a little bit of a hostile environment for me because, as it's written, I don't see how this isn't circumventing an AfD that received a sufficient amount of participation and was closed yesterday, started by an editor who I greatly respect but was heavily involved in that AfD (I was also involved as the list creator). It claims it was created at the behest of an admin, but then the admin came here and commented that wasn't what they said. (And if that's going to be the case, shouldn't all the AfD and WikiProject Olympics thread commenters be pinged...?) I desperately want to achieve consensus on having a list of Olympians, including making concessions if needed, but I want to do it the right way.
From a bigger picture it seems this list is being used as a 'proxy battle' among inclusionists and deletionists w.r.t. WP:NSPORTS2022 and its recent implementation this year, resulting in hundreds of Olympian articles being deleted and no suitable place to put that lost information. As someone who genuinely tries to look at each case on its merits, I don't know how to rectify that.
One of the biggest concerns I heard was editors saying they would prefer if lists were created by sport rather than alphabetically. I also thought that originally, but after actually compiling it I realized that anything other than an alphabetic list is guaranteed to create duplicate rows (e.g. for multi-sport athletes who would be listed in more than one of these articles) and thus introduce unforeseen complexities.
Nonetheless I did some of the legwork on this over the last few days to determine what that would look like. The largest Olympic list segment currently is 2,136 rows, a limit that was essentially decided by the community as others have split the original segments that were longer. Using that limit of about 2,100 rows per article, we would need more than one article for each sport, even if broken up further by gender. My best idea after that is to split by year and gender, so here's what that would look like in a ToC table with that approximate limit: Special:Diff/1311981102
This would result in duplicates both across sports and across years, but is the only way I can think of to split by sport. I'm not opposed to creating all those pages, just struggling to see how that would be better or more maintainable than the current list. --Habst (talk) 01:01, 18 September 2025 (UTC)[reply]
Thank you for validating my confusion. The question seems to be "Should we create these articles?" but then the already-existing articles are linked to. The answer would then logically be "No, they already exist." 207.11.240.2 (talk) 12:29, 19 September 2025 (UTC)[reply]

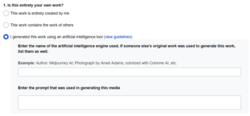
.html#/media/File%3AWikimedia_Commons_Special-UploadWizard_2025-08-28_01-15-32.png){kind=link}
 Display newcomer homepage. However disabling it also disables your homepage. isaacl (talk) 00:08, 16 September 2025 (UTC)
Display newcomer homepage. However disabling it also disables your homepage. isaacl (talk) 00:08, 16 September 2025 (UTC)